什么是目录遍历
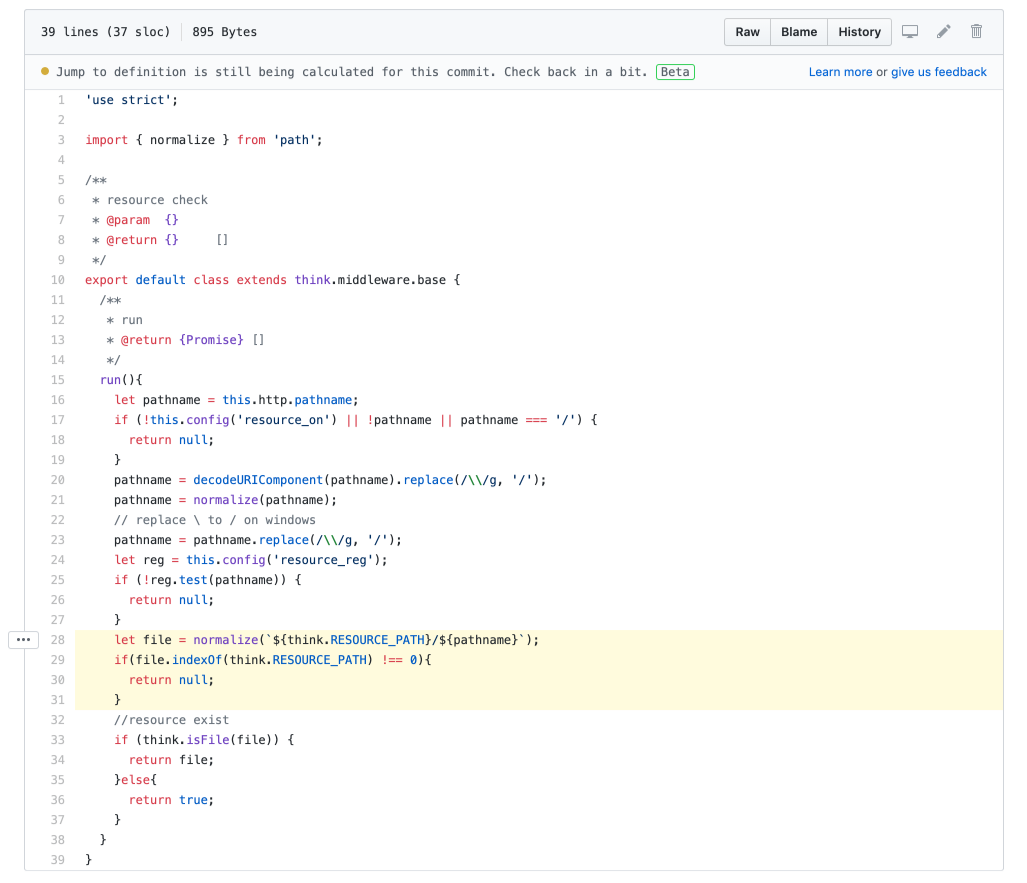
第一次接触到目录遍历漏洞还是在 ThinkJS 2 的时候。代码如下图,目的是当用户访问的 URL 是静态资源的时候返回静态资源的地址。其中 pathname 就是用户访问的 URL 中的路径,我们发现代码中只是简单的解码之后就在22行将其与资源目录做了拼接,这就是非常明显的目录遍历漏洞了。
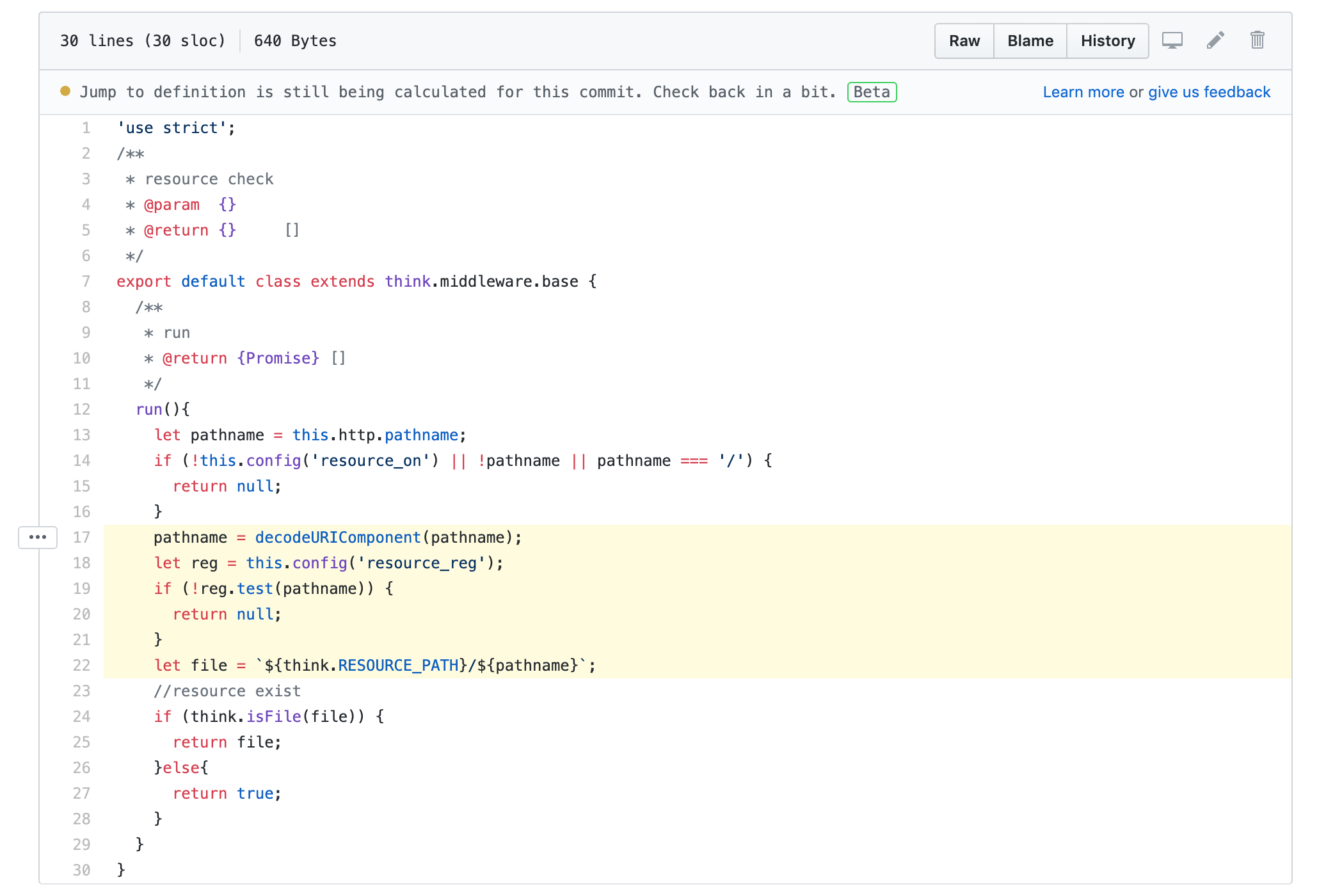
为什么这么说呢?假设用户访问的 URL 是 http://xxx.com/../../../xxx.jpg 的话最终返回的文件地址就会变成 think.RESOURCE_PATH 的上三层目录中的文件了。而这种利用网站的安全缺陷来列出服务器目录或者文件的方式就成为目录遍历漏洞(Directory traversal),也称之为路径遍历漏洞(英文:Path traversal)。
目录遍历在英文世界里又名…/ 攻击(Dot dot slash attack)、目录攀登(Directory climbing)及回溯(Backtracking)。其部分攻击手段也可划分为规范化攻击(Canonicalization attack)。 via: wikipedia
目录遍历的危害
目录遍历最大的危害是能够让任意用户访问系统的敏感文件,继而攻陷整个服务器。例如获取linux下的/etc/passwd文件后可能会破解出root用户的密码等。
防御方法
可以看到大部分情况下问题的关键就是 ../ 目录跳转符,所以防御的第一要务就是它进行过滤。除了过滤之外,还可以针对最终的文件路径进行判断,确保请求文件完整目录后的头N个字符与文档根目录完全相同,如果相同则返回内容,否则则可能是攻击地址不予返回。
回到文章开头说的那个代码问题,最终就是通过上述方法修复的,对最终的文件地址进行规范化后判断开头是否包含 RESOURCE_PATH 目录,如果不包含则返回空。