

【项目】Node.js + Electron 撸个OCR工具
背景
朋友工作总要找资料什么的,大多是pdf扫描版格式,无法复制,需要转成word或者文字,但由于其人穷,又不买那些pdf在线转换word的工具。得知后,帮助开发一个工具给她使用。
支持功能
- image ocr
node test/ocr.test.js(图片文字提取) - converting scanned PDF’s to an image (扫描版PDF转为图片后文字提取,同下)
- support pdf ocr
node test/pdf.test.js(PDF 文字提取) - support electron desktop packager (Electron打包为Desktop App)
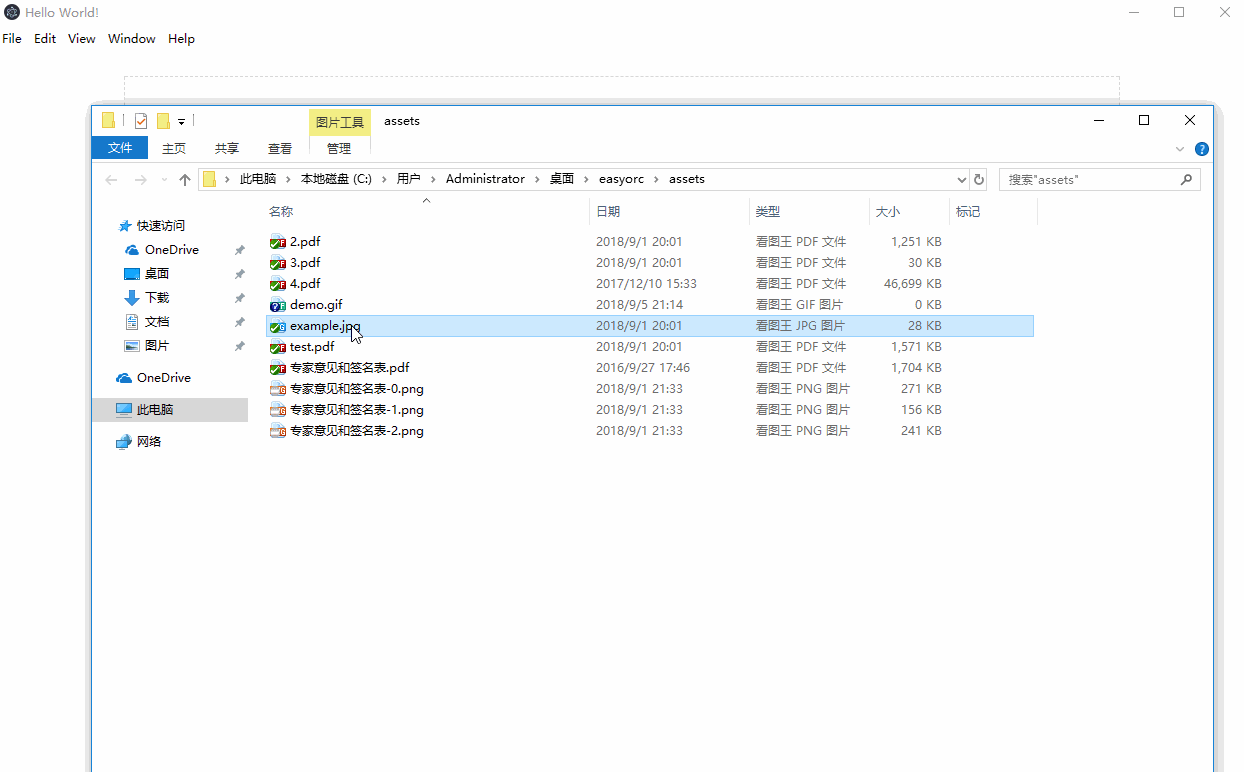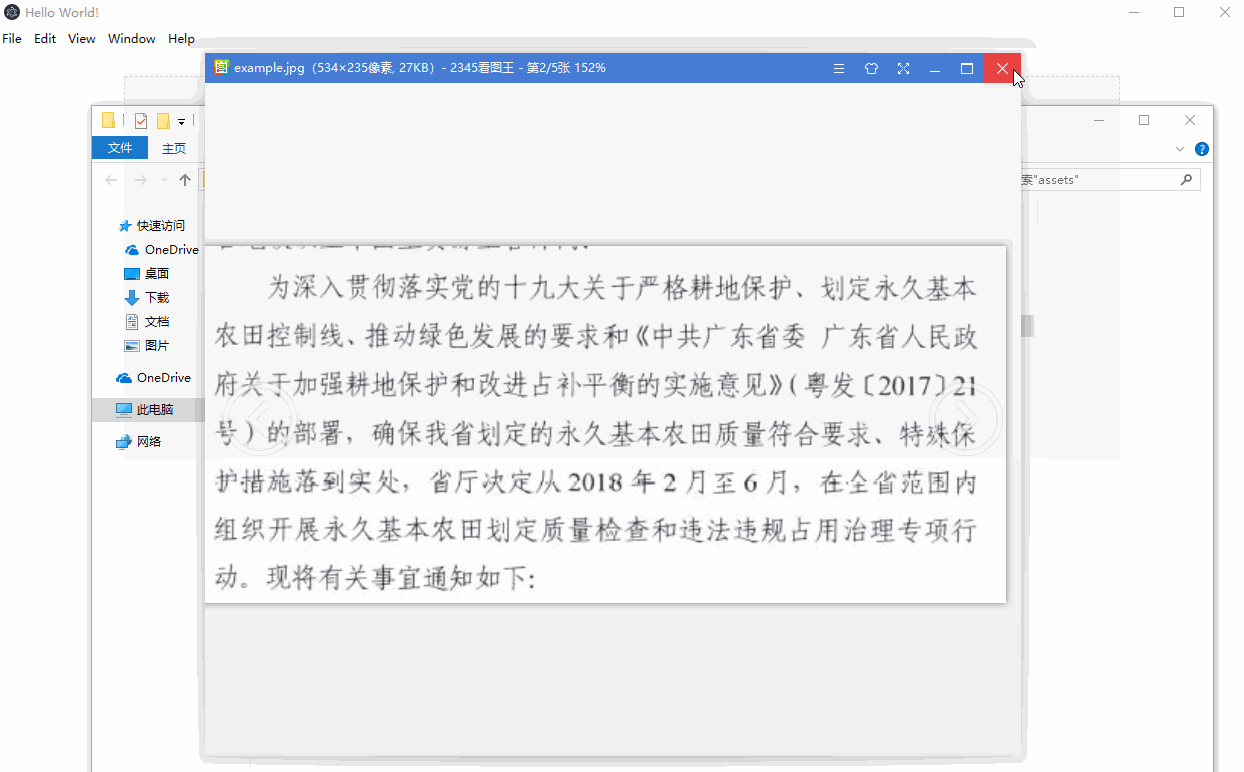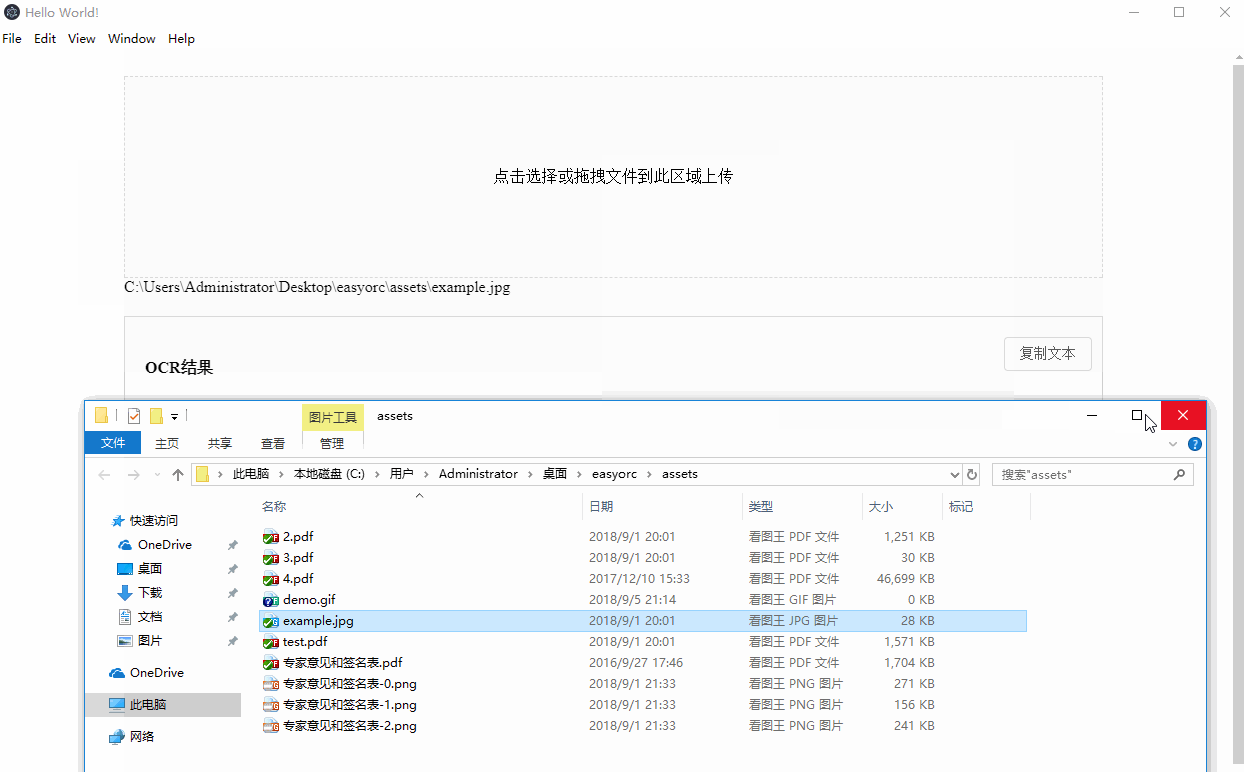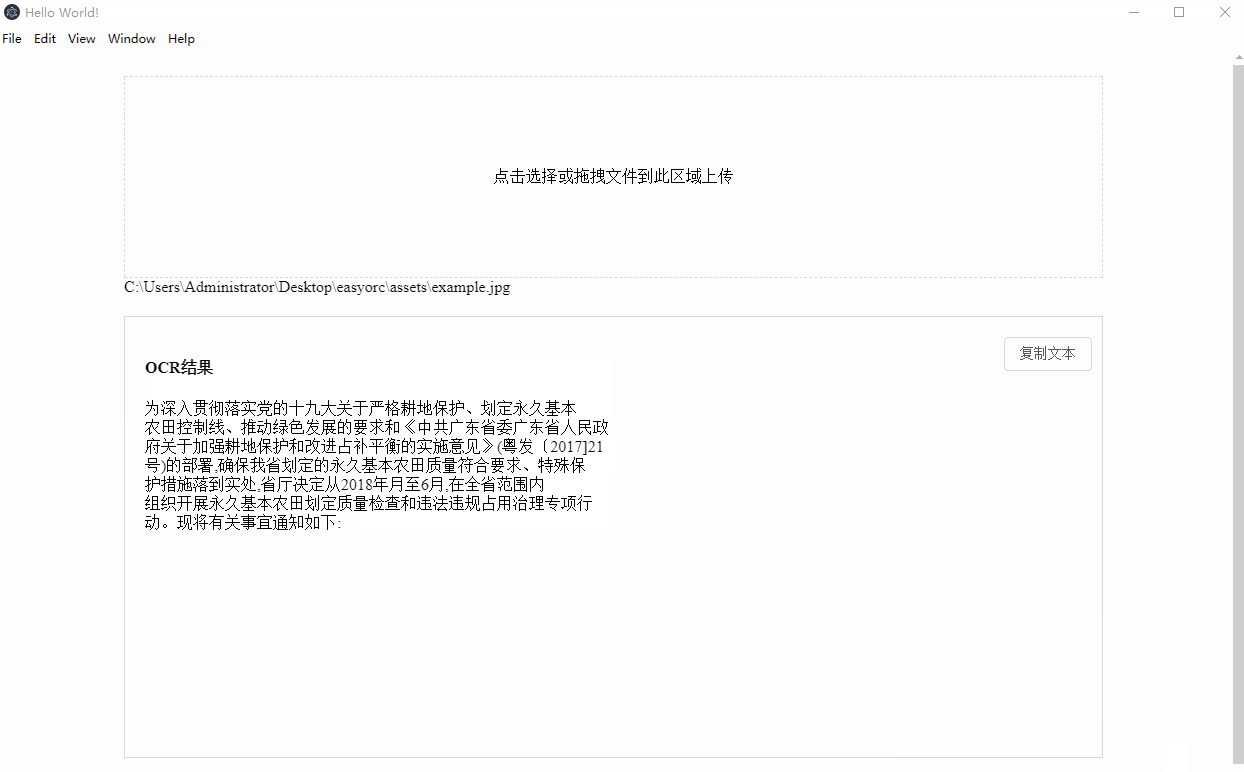
Demo 截图

实现过程介绍
本项目基于百度AIP平台,OCR接口
图片OCR 提取文字
这个简单,直接走百度OCR即可得到结果。node.js调用SDK而已
正常格式PDF
这个通过pdfinfo 工具 + GraphicsMagick 来实现,pdfinfo获取pdf文件信息(分页信息等),GraphicsMagick 将pdf作为图片(处理图片很强大)。
扫描版PDF
这个麻烦是在 pdfinfo 工具是无法获取pdf文件信息的,需要代码做兼容情况处理。扫描版PDF最终还是转换图片后再OCR提取文字。
源码
详细使用方式阅读README.md
https://github.com/giscafer/easyocr
一年多不逛cnode了,回来看看,顺便分享这个demo,也是这几天开发的。
9 回复


@yuu2lee4 犀利。。。
electron 体积大是硬伤,网上有一些优化方式,但是效果不是很显著,记得github看到过一个新的工具,目的是解决electron体积问题的。想找但找不着了


