
mongodb分页很简单,本文主要讲分页可能遇到的问题,以及优化方案
从传统web到移动端api,我们都面临一样的问题,比如ajax get有大小显示等,都会强迫你不得不分页
比如我的项目使用ratchet做h5框架,它的push.js里就是ajax get加载其他页面,页面太大就会报错。
分页说明
以典型的列表api来说:下拉刷新是获取最新信息,然后上拉加载下一页
常见api要写的2个接口
- get_latest(model,count)
- get_with_page(number,size)
get_latest一般是取最新的数据,比如我们常见的下拉刷新,一般都是这样的接口的。由于2次下拉之间,可能非常长的时间间隔,所以取到的数据会把当前列表的数据冲掉。
通常做法
- 如果n(比如n=30s)分钟内有连续请求,提示最近已更新,没必要再刷,或者直接返回当前数据
- 如果取到新数据,将当前列表的数据冲掉,保证数据一致性
如果判断我到最后一页了
常见的办法是取出总数,除以pagesize,然后判断当前页是否和总页数-1
n = all_count - 1
量少的时候,毫无感觉,如果量大了,你去查一下count(*)是啥后果呢?
所以比较好的做法是按照id去查,前端根据每次返回的数据条数,如果条数等于pagesize,你就可以取下一页数据,相反,如果取到的数据小于pagesize,你就知道没有那么多数据可以取了,即到了尾页。此时只要disable获取下一页的按钮即可。
使用 skip() 和 limit() 实现
//Page 1
db.users.find().limit (10)
//Page 2
db.users.find().skip(10).limit(10)
//Page 3
db.users.find().skip(20).limit(10)
........
抽象一下就是:检索第n页的代码应该是这样的
db.users.find().skip(pagesize*(n-1)).limit(pagesize)
当然,这是假定在你在2次查询之间没有任何数据插入或删除操作,你的系统能么?
当然大部分oltp系统无法确定不更新,所以skip只是个玩具,没太大用
而且skip+limit只适合小量数据,数据一多就卡死,哪怕你再怎么加索引,优化,它的缺陷都那么明显。
如果你要处理大量数据集,你需要考虑别的方案的。
使用 find() 和 limit() 实现
之前用skip()方法没办法更好的处理大规模数据,所以我们得找一个skip的替代方案。
为此我们想平衡查询,就考虑根据文档里有的时间戳或者id
在这个例子中,我们会通过‘_id’来处理(用时间戳也一样,看你设计的时候有没有类似created_at这样的字段)。
‘_id’是mongodb ObjectID类型的,ObjectID 使用12 字节的存储空间,每个字节两位十六进制数字,是一个24 位的字符串,包括timestamp, machined, processid, counter 等。下面会有一节单独讲它是怎么构成的,为啥它是唯一的。
使用_id实现分页的大致思路如下
- 在当前页内查出最后1条记录的_id,记为last_id
- 把记下来的last_id,作为查询条件,查出大于last_id的记录作为下一页的内容
这样来说,是不是很简单?
代码如下
//Page 1
db.users.find().limit(pageSize);
//Find the id of the last document in this page
last_id = ...
//Page 2
users = db.users.find({'_id'> last_id}). limit(10);
//Update the last id with the id of the last document in this page
last_id = ...
这只是示范代码,我们来看一下在Robomongo 0.8.4客户端里如何写
db.usermodels.find({'_id' :{ "$gt" :ObjectId("55940ae59c39572851075bfd")} }).limit(20).sort({_id:-1})
根据上面接口说明,我们仍然要实现2个接口
- get_latest(model,count)
- get_next_page_with_last_id(last_id, size)
为了让大家更好的了解根据‘_id’分页原理,我们有必要去了解ObjectID的组成。
关于 ObjectID组成
前面说了:‘_id’是mongodb ObjectID类型的,它由12位结构组成,包括timestamp, machined, processid, counter 等。
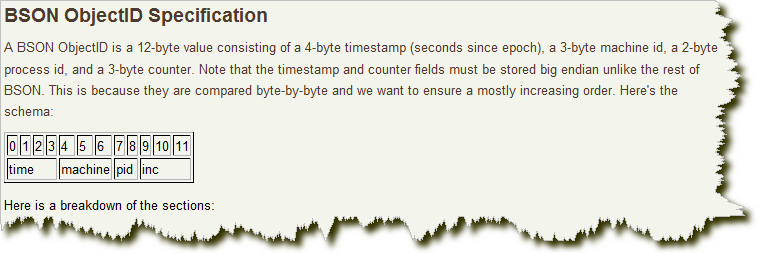
TimeStamp
前 4位是一个unix的时间戳,是一个int类别,我们将上面的例子中的objectid的前4位进行提取“4df2dcec”,然后再将他们安装十六进制 专为十进制:“1307761900”,这个数字就是一个时间戳,为了让效果更佳明显,我们将这个时间戳转换成我们习惯的时间格式
$ date -d ‘1970-01-01 UTC 1307761900 sec’ -u 2011年 06月 11日 星期六 03:11:40 UTC
前 4个字节其实隐藏了文档创建的时间,并且时间戳处在于字符的最前面,这就意味着ObjectId大致会按照插入进行排序,这对于某些方面起到很大作用,如 作为索引提高搜索效率等等。使用时间戳还有一个好处是,某些客户端驱动可以通过ObjectId解析出该记录是何时插入的,这也解答了我们平时快速连续创 建多个Objectid时,会发现前几位数字很少发现变化的现实,因为使用的是当前时间,很多用户担心要对服务器进行时间同步,其实这个时间戳的真实值并 不重要,只要其总不停增加就好。
Machine
接下来的三个字节,就是 2cdcd2 ,这三个字节是所在主机的唯一标识符,一般是机器主机名的散列值,这样就确保了不同主机生成不同的机器hash值,确保在分布式中不造成冲突,这也就是在同一台机器生成的objectid中间的字符串都是一模一样的原因。
pid
上面的Machine是为了确保在不同机器产生的objectid不冲突,而pid就是为了在同一台机器不同的mongodb进程产生了objectid不冲突,接下来的0936两位就是产生objectid的进程标识符。
increment
前面的九个字节是保证了一秒内不同机器不同进程生成objectid不冲突,这后面的三个字节a8b817,是一个自动增加的计数器,用来确保在同一秒内产生的objectid也不会发现冲突,允许256的3次方等于16777216条记录的唯一性。
客户端生成
mongodb产生objectid还有一个更大的优势,就是mongodb可以通过自身的服务来产生objectid,也可以通过客户端的驱动程序来产生,如果你仔细看文档你会感叹,mongodb的设计无处不在的使
用空间换时间的思想,比较objectid是轻量级,但服务端产生也必须开销时间,所以能从服务器转移到客户端驱动程序完成的就尽量的转移,必须将事务扔给客户端来完成,减低服务端的开销,另还有一点原因就是扩展应用层比扩展数据库层要变量得多。
总结
mongodb的ObejctId生产思想在很多方面挺值得我们借鉴的,特别是在大型分布式的开发,如何构建轻量级的生产,如何将生产的负载进行转移,如何以空间换取时间提高生产的最大优化等等。
说这么多的目的就是告诉你:mongodb的_id为啥是唯一的,单机如何唯一,集群中如何唯一,理解了这个就可以了。
性能优化
索引
按照自己的业务需求即可,参见官方文档 http://docs.mongodb.org/manual/core/indexes/
关于explain
rdbms里的执行计划,如果你不了解,那么mongo的explain估计你也不太熟,简单说几句
explain是mongodb提供的一个命令,用来查看查询的过程,以便进行性能优化。
http://docs.mongodb.org/manual/reference/method/cursor.explain/
db.usermodels.find({'_id' :{ "$gt" :ObjectId("55940ae59c39572851075bfd")} }).explain()
/* 0 */
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "xbm-wechat-api.usermodels",
"indexFilterSet" : false,
"parsedQuery" : {
"_id" : {
"$gt" : ObjectId("55940ae59c39572851075bfd")
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"_id" : [
"(ObjectId('55940ae59c39572851075bfd'), ObjectId('ffffffffffffffffffffffff')]"
]
}
}
},
"rejectedPlans" : []
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 5,
"executionTimeMillis" : 0,
"totalKeysExamined" : 5,
"totalDocsExamined" : 5,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 5,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 5,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"docsExamined" : 5,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 5,
"executionTimeMillisEstimate" : 0,
"works" : 5,
"advanced" : 5,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"_id" : [
"(ObjectId('55940ae59c39572851075bfd'), ObjectId('ffffffffffffffffffffffff')]"
]
},
"keysExamined" : 5,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0
}
},
"allPlansExecution" : []
},
"serverInfo" : {
"host" : "iZ251uvtr2b",
"port" : 27017,
"version" : "3.0.3",
"gitVersion" : "b40106b36eecd1b4407eb1ad1af6bc60593c6105"
}
}
字段说明:
queryPlanner.winningPlan.inputStage.stage列显示查询策略
- IXSCAN表示使用Index 查询
- COLLSCAN表示使用列查询,也就是一个一个对比过去
cursor中的索引名称移动到了queryPlanner.winningPlan.inputStage.indexName
3.0中使用executionStats.totalDocsExamined来显示总共需要检查的文档数,用以取而代之2.6里的nscanned,即扫描document的行数。
- nReturned:返回的文档行数
- needTime:耗时(毫秒)
- indexBounds:所用的索引
Profiling
另外还有一个Profiling功能
db.setProfilingLevel(2, 20)
profile级别有三种:
- 0:不开启
- 1:记录慢命令,默认为大于100ms
- 2:记录所有命令
- 3、查询profiling记录
默认记录在system.profile中
db['system.profile'].find()
总结一下
- explain在写代码阶段就可以做性能分析,开发阶段用
- profile检测性能慢的语句,便于线上产品问题定位
无论哪种你定位出来问题,解决办法
- 根据业务,调整schema结构
- 优化索引
有了上面这些知识,相信大家能够自己去给分页语句测试性能了。
全文完
欢迎关注我的公众号【node全栈】

