

0 修订
0.1 修订说明
文章发表之后,也难免会有一些新的想法。如果新开一篇文章,会显得散乱;而直接修改正文,那些已经阅读过本篇文章的读者又无法快速定位修改的内容。因此,新增修订章节,记录修订历史
0.2 修订历史
0.2.1 2019-06-18 亮点与痛点
1)亮点
CabloyJS最大的亮点是:通过pc=mobile+pad的模式,把mobile场景的操控体验和开发模式带⼊pc场景。既显著减少了代码开发量,提升了开发效率,⼜保持了用户操控体验的⼀致性

2)痛点
CabloyJS最大的痛点是:通过模块化的架构设计,可以快速开发全场景业务
| 场景 | 前端 | 后端 |
|---|---|---|
| PC:Web | CabloyJS前端 | CabloyJS后端 |
| PC:Exe | CabloyJS前端 + Electron | CabloyJS后端 |
| Mobile:IOS | CabloyJS前端 + Cordova | CabloyJS后端 |
| Mobile:Android | CabloyJS前端 + Cordova | CabloyJS后端 |
| 微信公共号 | CabloyJS前端 + 微信API | CabloyJS后端 |
| 企业微信 | CabloyJS前端 + 微信API | CabloyJS后端 |
| 钉钉 | CabloyJS前端 + 钉钉API | CabloyJS后端 |
| Slack | CabloyJS前端 + Slack API | CabloyJS后端 |
| 小程序:微信、支付宝、百度等 | 小程序框架 | CabloyJS后端 |
- 后端:由于完整的前后端分离设计,只需开发一套CabloyJS后端代码即可
- 前端:所有可基于H5的场景,只需开发一套CabloyJS前端代码即可
1 基本概念
1.1 CabloyJS是什么
1.1.1 定义
CabloyJS是一款顶级NodeJS全栈业务开发框架
1.1.2 特点
- CabloyJS是采用NodeJS进行全栈开发的最佳实践
- CabloyJS不重复造轮子,而是采用业界最新的开源技术,进行全栈开发的最佳组合
- CabloyJS前端采用VueJS + Framework7 + WebPack,后端采用KoaJS + EggJS,数据库采用MySQL
- CabloyJS时刻跟踪开源技术的最新成果,并持续优化,使整个框架时刻保持最佳状态
1.1.3 理念
既可快速开发,又可灵活定制
为了实现此理念,CabloyJS内置开发了大量核心模块,使您可以在最短的时间内架构一个完整的Web项目。比如,当您新建一个Web项目时,就已经具备完整的用户登录与认证系统,也具有验证码功能,同时也具备用户管理、角色管理、权限管理等功能
此外,这些内置模块提供了灵活的定制特性,您也可以开发全新的模块来替换内置模块,从而实现系统的定制化
1.2 CabloyJS核心解决什么问题
- 场景碎片化
- 业务模块化
1.2.1 场景碎片化
1) 先说说Mobile场景
我们知道,随着智能机的日益普及,咱们开发人员所面对的需求场景与开发场景日益碎片化,如浏览器、IOS、Android,还有大量第三方平台:微信、企业微信、钉钉、Facebook、Slack等等
随着智能设备性能越来越好,网速越来越快,针对如此众多的开发场景,采用H5开发必将是大势所趋。只需开发一套代码,就可以在以上所有智能设备中运行,不仅可以显著减少开发量,同时也可以显著提升开发效率,对开发团队和终端用户均是莫大的福利
2) 再来谈谈PC场景
以上咱们说H5开发,只需开发一套代码,就可以在所有智能设备中运行。但是还有一个开发场景没有得到统一:那就是PC场景
由于屏幕显示尺寸的不同,PC场景和Mobile场景有着不同的操作风格。有些前端UI框架,采用“自适应”策略,为PC场景开发的页面,在Mobile场景下虽然也能查看和使用,但使用体验往往差强人意
这也就是为什么有些前端框架总是成对出现的原因:如Element-UI和Mint-UI,如AntDesign和AntDesign-Mobile
这也就意味着,当我们同时面对PC场景和Mobile场景时,仍然需要开发两套代码。在面对许多开发需求时,这些重复的工作量往往是难以接受的:
- 比如,我们在企业微信或钉钉上开发一些H5业务应用,同时也希望这些应用也可以在PC端浏览器中运行
- 比如,我们为微信公共号开发了一些H5业务应用,同时也希望这些应用也可以在PC端浏览器中运行。同时,还可以在同一架构下开发后台管理类功能,通过区别不同的登录用户、不同的使用场景,从而显示不同的前端页面
3) PC = MOBILE + PAD
CabloyJS前端采用Framework7框架,目前已同步升级到最新版Framework7 V4。CabloyJS在Framework7的基础上进行了巧妙的扩展,将PC端的页面切分为多个区域,实现了多个Mobile和PAD同时呈现在一个PC端的效果。换句话说,你买了一台Mac,就相对于买了多台IPhone和IPad,用多个虚拟的移动设备同时工作,即显著提升了工作效率,也提供了非常有趣的使用体验
4) 实际效果
有图有真相
也可PC端体验
也可手机扫描体验

5) 如何实现的
CabloyJS是模块化的全栈框架,为了实现PC = MOBILE + PAD的风格,内置了两个模块:egg-born-module-a-layoutmobile和egg-born-module-a-layoutpc。当前端框架加载完毕,会自动判断当前页面的宽度(称为breakpoint),如果小于800,使用Mobile布局,如果大于800,使用PC布局,而且breakpoint数值可以自定义
此外,这两个布局模块本身也有许多参数可以自定义,甚至,您也可以开发自己的布局模块,替换掉内置的实现方式
下面分别贴出两个布局模块的默认参数,相信您一看便知他们的用处
egg-born-module-a-layoutmobile
export default {
layout: {
login: '/a/login/login',
loginOnStart: true,
toolbar: {
tabbar: true, labels: true, bottom: true,
},
tabs: [
{ name: 'Home', tabLinkActive: true, iconMaterial: 'home', url: '/a/base/menu/list' },
{ name: 'Atom', tabLinkActive: false, iconMaterial: 'group_work', url: '/a/base/atom/list' },
{ name: 'Mine', tabLinkActive: false, iconMaterial: 'person', url: '/a/user/user/mine' },
],
},
};
egg-born-module-a-layoutpc
export default {
layout: {
login: '/a/login/login',
loginOnStart: true,
header: {
buttons: [
{ name: 'Home', iconMaterial: 'dashboard', url: '/a/base/menu/list', target: '_dashboard' },
{ name: 'Atom', iconMaterial: 'group_work', url: '/a/base/atom/list' },
],
mine:
{ name: 'Mine', iconMaterial: 'person', url: '/a/user/user/mine' },
},
size: {
small: 320,
top: 60,
spacing: 10,
},
},
};
1.2.2 业务模块化
NodeJS的蓬勃发展,为前后端开发带来了更顺畅的体验,显著提升了开发效率。但仍有网友质疑NodeJS能否胜任大型Web应用的开发。大型Web应用的特点是随着业务的增长,需要开发大量的页面组件。面对这种场景,一般有两种解决方案:
- 采用单页面的构建方式,缺点是产生的部署包很大
- 采用页面异步加载方式,缺点是页面过于零散,需要频繁从后端获取JS资源
CabloyJS实现了第三种解决方案:
- 页面组件按业务需求归类,进行模块化,并且实现了模块的异步加载机制,从而弥合了前两种解决方案的缺点,完美满足大型Web应用业务持续增长的需求
在CabloyJS中,一切业务开发皆以业务模块为单位。比如,我们要开发一个CMS建站工具,就新建一个业务模块,如已经实现的模块egg-born-module-a-cms。该CMS模块包含十多个Vue页面组件,在正式发布时,就会构建成一个JS包。在运行时,只需异步加载这一个JS包,就可以访问CMS模块中任何一个Vue页面组件了。
因此,在一个大型的Web系统中,哪怕有数十甚至上百个业务模块,按CabloyJS的模块化策略进行代码组织和开发,既不会出现单一巨大的部署包,也不会出现大量碎片化的JS构建文件。
CabloyJS的模块化系统还有如下显著的特点:
1) 零配置、零代码
也就是说,前面说到的模块化异步打包策略是已经精心调校好的系统核心特性,我们只需像平时一样开发Vue页面组件,在构建时系统会自动进行模块级别的打包,同时在运行时进行异步加载
我们仍然以CMS模块为例,通过缩减的代码直观的看一下代码风格,如果想了解进一步的细节,可以直接查看对应的源码(下同,不再赘述)
如何查看源码:进入项目的node_modules目录,查看
egg-born-为前缀的模块源码即可
egg-born-module-a-cms/src/module/a-cms/front/src/routes.js
function load(name) {
return require(`./pages/${name}.vue`).default;
}
export default [
{ path: 'config/list', component: load('config/list') },
{ path: 'config/site', component: load('config/site') },
{ path: 'config/siteBase', component: load('config/siteBase') },
{ path: 'config/language', component: load('config/language') },
{ path: 'config/languagePreview', component: load('config/languagePreview') },
{ path: 'category/list', component: load('category/list') },
{ path: 'category/edit', component: load('category/edit') },
{ path: 'category/select', component: load('category/select') },
{ path: 'article/contentEdit', component: load('article/contentEdit') },
{ path: 'article/category', component: load('article/category') },
{ path: 'article/list', component: load('article/list') },
{ path: 'article/post', component: load('article/post') },
{ path: 'tag/select', component: load('tag/select') },
{ path: 'block/list', component: load('block/list') },
{ path: 'block/item', component: load('block/item') },
];
可以看到,在前端页面路由的定义中,仍然是采用平时的同步加载写法
关于模块的异步加载机制是由核心模块egg-born-front来完成的,参见源码egg-born-front/src/base/module.js
2) 模块自洽、即插即用
每个业务模块都是自洽的整体,包含与本模块业务相关的前端代码和后端代码,而且采用前后端分离模式
模块自洽既有利于自身的高度内聚,也有利于整个系统的充分解耦。业务模块只需要考虑自身的逻辑实现,容易实现业务的充分沉淀与分享,达到即插即用的效果
举一个例子:如果我们要开发文件上传功能,当我们在网上找到合适的上传组件之后,在自己的项目中使用时,仍然需要开发大量对接代码。也就是说,在网上找到的上传组件没有实现充分的沉淀,不是自洽的,也就不能实现便利的分享,达到即插即用的效果
而CabloyJS内置的的文件上传模块egg-born-module-a-file就实现了功能的充分沉淀。为什么呢?因为业务模块本身就包含前端代码和后端代码,能够施展的空间很大,可以充分细化上传逻辑
因此,在CabloyJS中要调用文件上传功能,就会变得极其便捷。以CMS模块为例,上传图片并取得图片URL,只需短短20行代码
egg-born-module-a-cms/src/module/a-cms/front/src/pages/article/contentEdit.vue
...
onUpload(mode, atomId) {
return new Promise((resolve, reject) => {
this.$view.navigate('/a/file/file/upload', {
context: {
params: {
mode,
atomId,
},
callback: (code, data) => {
if (code === 200) {
resolve({ text: data.realName, addr: data.downloadUrl });
}
if (code === false) {
reject();
}
},
},
});
});
},
...
3) 模块隔离
在大型Web项目中,不可避免的要考虑各类资源、各种变量、各个实体之间命名的冲突问题。针对这个问题,不同的开发团队大都会规范各类实体的命名规范。随着项目的扩充,这种命名规范仍然会变得很庞杂。如果我们面对的是一个开放的系统,使用的是来自不同团队开发的模块,所面临的命名冲突的风险就会越发严重
CabloyJS使用了一个巧妙的设计,一劳永逸解决了命名冲突的隐患。在CabloyJS中,业务模块采用如下命名规范:
egg-born-module-{providerId}-{moduleName}
providerId: 开发者Id,强烈建议采用Github的Username,从而确保贡献到社区的模块不会冲突moduleName: 模块名称
由于模块自洽的设计机制,我们只需要解决模块命名的唯一性问题,在进行模块开发时就不会再被命名冲突的困扰所纠缠了
比如,CMS模块提供了一个前端页面路由config/list。很显然,如此简短的路径,在其他业务模块中出现的概率非常高。但在CabloyJS中,如此命名就不会产出冲突。在CMS模块内部进行页面跳转时,可以直接使用config/list,这称之为相对路径引用。但是,如果其他业务模块也想跳转至此页面就使用/a/cms/config/list,这称之为绝对路径引用
再比如,前面的例子我们要调用上传文件页面,就是采用绝对路径:/a/file/file/upload
模块隔离是业务模块的核心特性。这是因为,模块前端和后端有大量实体都需要进行这种隔离。CabloyJS从系统层面完成了这种隔离的机制,从而使得我们在实际的模块业务开发时可以变得轻松、便捷。
模块前端隔离机制
模块前端的隔离机制由模块egg-born-front来完成,实现了如下实体的隔离:
模块后端隔离机制
模块后端的隔离机制由模块egg-born-backend来完成,实现了如下实体的隔离:
后端Service隔离,不仅是解决命名冲突的需要,更是性能提升方面重要的考量。
比如有50个业务模块,每个模块有20个Service,这样全局就有1000个Service。 在EggJS中,这1000个Service需要一次性预加载以便供Controller代码调用。CabloyJS就在EggJS的基础上做了隔离处理,如果是模块A的Controller,只需要预加载模块A的20个Service,供模块A的Controller调用。这样,就实现了一举两得:不仅命名隔离,而且性能提升,从而满足大型Web系统开发的需求
- 后端Model:参见
后端Model是CabloyJS实现的访问数据实体的便捷工具,在Model的定义和使用上,都比Sequelize简洁、高效
与后端Service一样,后端Model也实现了命名隔离,同时也只能被模块自身的Controller和Service调用
4) 快速的前端构建
CabloyJS采用WebPack进行项目的前端构建。由于CabloyJS项目是由一系列业务模块组成的,因此,可以把模块代码提前预编译,从而在构建整个项目的前端时就可以显著提升构建速度
经实践,如果一个项目包含40个业务模块,如果按照普通的构建模式需要70秒构建完成。而采用预编译的机制,则只需要20秒即可完成。这对于开发大型Web项目具有显著的工程意义
5) 保护商业代码
CabloyJS中的业务模块,不仅前端代码可以构建,后端代码也可以用WebPack进行构建。后端代码在构建时,也可以指定是否丑化,这种机制可以满足保护商业代码的需求
CabloyJS后端的基础是EggJS,是如何做到可以编译构建的呢?
CabloyJS后端在EggJS的基础上进行了扩展,每个业务模块都有一个入口文件main.js,通过main.js串联后端所有JS代码,因此可以轻松实现编译构建
1.3 CabloyJS的开发历程
1.3.1 两阶段
CabloyJS从2016年启动开发,主要历经两个开发阶段:
1) 第一阶段:EggBornJS
EggBornJS关注的核心就是实现一套完整的以业务模块为核心的全栈开发框架
比如模块egg-born-front是框架前端的核心模块,模块egg-born-backend是框架后端的核心模块,模块egg-born是框架的命令行工具,用于创建项目骨架
这也是为什么所有业务模块都是以egg-born-module-为命名前缀的原因
2) 第二阶段:CabloyJS
EggBornJS只是一个基础的全栈开发框架,如果要进行业务开发,还需要考虑许多与业务相关的支撑特性,如:用户管理、角色管理、权限管理、菜单管理、参数设置管理、表单验证、登录机制,等等。特别是在前后端分离的场景下,对权限管理的要求就提升到一个更高的水平
CabloyJS在EggBornJS的基础上,提供了一套核心业务模块,从而实现了一系列业务支撑特性,并将这些特性进行有机的组合,形成完整而灵活的上层生态架构,从而支持具体的业务开发进程
换句话说,从实质上看,CabloyJS是一组核心业务模块的组合,从形式上看,CabloyJS是一组模块依赖项。且看CabloyJS的package.json文件:
cabloy/package.json
{
"name": "cabloy",
"version": "2.1.2",
"description": "The Ultimate Javascript Full Stack Framework",
...
"author": "zhennann",
"license": "ISC",
...
"dependencies": {
"egg-born-front": "^4.1.0",
"egg-born-backend": "^2.1.0",
"egg-born-bin": "^1.2.0",
"egg-born-scripts": "^1.1.0",
"egg-born-module-a-version": "^2.2.2",
"egg-born-module-a-authgithub": "^2.0.3",
"egg-born-module-a-authsimple": "^2.0.3",
"egg-born-module-a-base-sync": "^2.0.10",
"egg-born-module-a-baseadmin": "^2.0.3",
"egg-born-module-a-cache": "^2.0.3",
"egg-born-module-a-captcha": "^2.0.4",
"egg-born-module-a-captchasimple": "^2.0.3",
"egg-born-module-a-components-sync": "^2.0.5",
"egg-born-module-a-event": "^2.0.2",
"egg-born-module-a-file": "^2.0.2",
"egg-born-module-a-hook": "^2.0.2",
"egg-born-module-a-index": "^2.0.2",
"egg-born-module-a-instance": "^2.0.2",
"egg-born-module-a-layoutmobile": "^2.0.2",
"egg-born-module-a-layoutpc": "^2.0.2",
"egg-born-module-a-login": "^2.0.2",
"egg-born-module-a-mail": "^2.0.2",
"egg-born-module-a-markdownstyle": "^2.0.3",
"egg-born-module-a-mavoneditor": "^2.0.2",
"egg-born-module-a-progress": "^2.0.2",
"egg-born-module-a-sequence": "^2.0.2",
"egg-born-module-a-settings": "^2.0.2",
"egg-born-module-a-status": "^2.0.2",
"egg-born-module-a-user": "^2.0.3",
"egg-born-module-a-validation": "^2.0.4",
"egg-born-module-test-cook": "^2.0.2"
}
}
相信您通过这些核心模块的名称,就已经猜到这些模块的用处了
1.3.2 整体架构图
根据前面两阶段的分析,我们就可以勾勒出框架的整体架构图
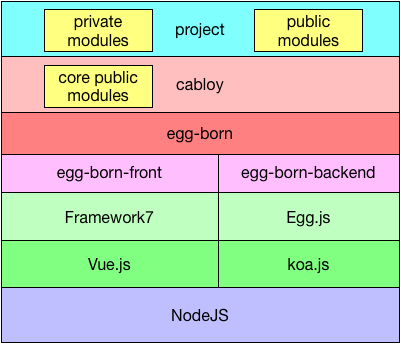
这种架构,让整个体系变得层次分明,也让实际的Web项目的源代码文件组织结构变得非常简洁直观。大量的架构细节都封装在EggBornJS中,而我们的Web项目只需要引用一个CabloyJS即可,CabloyJS负责引用架构中其他核心模块
这种架构,也让实际的Web项目的升级变得更加容易,具体如下:
1) 删除现有模块依赖项
$ rm -rf node_modules
2) 如果有此文件,建议删除
$ rm -rf package-lock.json
3) 重新安装所有模块依赖项
$ npm i
1.3.3 意义
有了EggBornJS,从此可复用的不仅仅是组件,还有业务模块
有了CabloyJS,您就可以快速开发各类业务应用
2 数据版本与开发流程
业务模块必然要处理数据并且存储数据,当然也不可避免会出现数据架构的变动,比如新增表、新增字段、删除字段、调整旧数据,等等
CabloyJS通过巧妙的数据版本控制,可以让业务模块在不断的迭代过程中,无缝的完成模块升级和数据升级
在数据版本的基础上,再配合一套开发流程,从而不论是在开发环境还是生产坏境,都能有顺畅的开发与使用体验
2.1 数据版本
2.1.1 数据版本定义
可以通过package.json指定业务模块的数据版本,以模块egg-born-module-test-cook为例
egg-born-module-test-cook/package.json
{
"name": "egg-born-module-test-cook",
"version": "2.0.2",
"eggBornModule": {
"fileVersion": 1,
"dependencies": {
"a-base": "1.0.0"
}
},
...
}
模块当前的数据版本fileVersion为1。当这个模块正式发布出去之后,为1的数据版本就处于封闭状态。当有新的迭代,需要改变模块的数据架构时,就需要将fileVersion递增为2。以此类推,从而完成模块数据架构的自动无缝升级
2.1.1 数据版本升级
当CabloyJS后端服务在启动时,会自动检测每个业务模块的数据版本,当存在数据版本变更时,就会自动调用业务模块的升级代码,从而完成自动升级。仍以模块egg-born-module-test-cook为例,其数据版本升级代码如下:
egg-born-module-test-cook/backend/src/service/version.js
...
async update(options) {
if (options.version === 1) {
let sql = `
CREATE TABLE testCook (
id int(11) NOT NULL AUTO_INCREMENT,
createdAt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
updatedAt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted int(11) DEFAULT '0',
iid int(11) DEFAULT '0',
atomId int(11) DEFAULT '0',
cookCount int(11) DEFAULT '0',
cookTypeId int(11) DEFAULT '0',
PRIMARY KEY (id)
)
`;
await this.ctx.model.query(sql);
sql = `
CREATE TABLE testCookType (
id int(11) NOT NULL AUTO_INCREMENT,
createdAt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
updatedAt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted int(11) DEFAULT '0',
iid int(11) DEFAULT '0',
name varchar(255) DEFAULT NULL,
PRIMARY KEY (id)
)
`;
await this.ctx.model.query(sql);
sql = `
CREATE VIEW testCookView as
select a.*,b.name as cookTypeName from testCook a
left join testCookType b on a.cookTypeId=b.id
`;
await this.ctx.model.query(sql);
sql = `
CREATE TABLE testCookPublic (
id int(11) NOT NULL AUTO_INCREMENT,
createdAt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
updatedAt timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted int(11) DEFAULT '0',
iid int(11) DEFAULT '0',
atomId int(11) DEFAULT '0',
PRIMARY KEY (id)
)
`;
await this.ctx.model.query(sql);
}
}
...
当数据版本变更时,CabloyJS后端调用方法update,通过判断属性options.version的值,进行对应版本的数据架构变更
2.2 开发流程
2.2.1 背景
那么问题来了?在模块开发阶段,如果需要变更数据架构怎么办呢?因为模块还没有正式发布,所以,不需要锁定数据版本。也就是说,如果当前数据版本fileVersion是1,那么在正式发布之前,不论进行多少次数据架构变更,fileVersion仍是1
一方面,我们肯定要修改方法update,加入架构变更的代码逻辑,比如添加表、添加字段等等
另一方面,我们还要修改当前测试数据库中的数据架构。因为fileVersion是没有变化的,所以当重启CabloyJS后端服务时,方法update并不会再次执行
针对这种情况,首先想到的是手工修改测试数据库中的数据架构。而CabloyJS提供了更优雅的机制
2.2.2 运行环境
我们知道EggJS提供了三个运行环境:测试环境、开发环境、生产环境。CabloyJS在EggJS的基础上,对这三个运行环境赋予了进一步的意义
1) 测试环境
- 测试环境的参数配置如下
{项目目录}/src/backend/config/config.unittest.js
module.exports = appInfo => {
const config = {};
...
// mysql
config.mysql = {
clients: {
// donnot change the name
__ebdb: {
host: '127.0.0.1',
port: '3306',
user: 'root',
password: '',
database: 'sys', // donnot change the name
},
},
};
...
return config;
};
- 命令行如下:
$ npm run test:backend
由于我们将测试环境的数据库名称设为sys,那么CabloyJS就会自动删除旧的测试数据库,建立新的数据库。因为是重新创建数据库,那么也就意味着fileVersion由0升级为1,从而触发方法update的执行,进而自动完成数据架构的升级
2) 开发环境
- 开发环境的参数配置如下
{项目目录}/src/backend/config/config.local.js
module.exports = appInfo => {
const config = {};
...
// mysql
config.mysql = {
clients: {
// donnot change the name
__ebdb: {
host: '127.0.0.1',
port: '3306',
user: 'root',
password: '',
database: 'sys', // recommended
},
},
};
...
return config;
};
- 命令行如下:
$ npm run dev:backend
虽然我们也将开发环境的数据库名称设为sys,但是CabloyJS会自动寻找最新创建的测试数据库,然后一直使用它
3) 生产环境
- 生产环境的参数配置如下
{项目目录}/src/backend/config/config.prod.js
module.exports = appInfo => {
const config = {};
...
// mysql
config.mysql = {
clients: {
// donnot change the name
__ebdb: {
host: '127.0.0.1',
port: '3306',
user: 'root',
password: '',
database: '{实际数据库名}',
},
},
};
...
return config;
};
- 命令行如下:
$ npm run start:backend
因为生产环境存储的都是实际业务数据,所以在生产环境就要设置实际的数据库名称了
2.2.3 开发流程的最佳实践
根据前面数据版本和运行环境的分析,我们就可以规划出一套关于开发流程的最佳实践:
- 当项目创建后,先执行一次
npm run test:backend,用于自动创建一个测试数据库 - 在进行常规开发时,执行
npm run dev:backend来启动项目后端服务,用于调试 - 如果模块数据版本需要变更,在修改完属性
fileVersion和方法update之后,再一次执行npm run test:backend,从而重建一个新的测试数据库 - 当项目需要在生产环境运行时,则运行
npm run start:backend来启动后端服务
3 特性鸟瞰
3.1 多实例与多域名
CabloyJS通过多实例的概念来支持多域名站点的开发。启动一个服务,可以支持多个实例运行。实例共享数据表架构,但运行中产生的数据是相互隔离的
这有什么好处呢?比如您用CabloyJS开发了一款CRM的SAAS服务,那么只需开发并运行一个服务,就可以同时服务多个不同的客户。每个客户一个实例,用一个单独的域名进行区分即可。
再比如,要想开发一款基于微信公共号的营销平台,提供给不同的客户使用,多实例与多域名是最自然、最有效的架构设计。
具体信息,请参见
3.2 数据库事务
3.2.1 EggJS事务处理方式
const conn = await app.mysql.beginTransaction(); // 初始化事务
try {
await conn.insert(table, row1); // 第一步操作
await conn.update(table, row2); // 第二步操作
await conn.commit(); // 提交事务
} catch (err) {
// error, rollback
await conn.rollback(); // 一定记得捕获异常后回滚事务!!
throw err;
}
3.2.2 CabloyJS事务处理方式
CabloyJS在EggJS的基础上进行了扩展,使得数据库事务处理变得更加自然,甚至可以说是无痛处理
在CabloyJS中,实际的代码逻辑不用考虑数据库事务,如果哪个后端API路由需要启用数据库事务,直接在API路由上声明一个中间件transaction即可,以模块egg-born-module-test-cook为例
egg-born-module-test-cook/backend/src/routes.js
...
{ method: 'get', path: 'test/echo/:id', controller: test, action: 'echo', middlewares: 'transaction' },
...
3.3 完美的用户与身份认证分离体系
3.3.1 通用的身份认证
CabloyJS把用户系统与身份认证系统完全分离,有如下好处:
- 支持众多身份认证机制:用户名/密码认证、手机认证、第三方认证(Github、微信)等等
- 可完全定制登录页面,自由组合各种身份认证机制
- 网站用户也可以自由添加不同的身份认证机制,也可以自由的删除
比如,
用户A先通过用户名/密码注册的身份,以后还可以添加Github、微信等认证方式
比如,
用户B先通过Github注册的身份,以后还可以添加用户名/密码等认证方式
3.3.2 通用的验证码机制
CabloyJS把验证码机制抽象了出来,并且提供了一个缺省的验证码模块egg-born-module-a-captchasimple,您也可以按统一规范开发自己的验证码模块,然后挂接到系统中
3.3.3 通用的邮件发送机制
CabloyJS也实现了通用的邮件发送功能,基于成熟的nodemailer。由于nodemailer内置了一个测试服务器,因此,在开发环境中,不需要真实的邮件发送账号,也可以进行系统的测试与调试
3.4 模块编译与发布
前面我们谈到CabloyJS中的业务模块是自洽的,可以单独编译打包,既可以显著提升整体项目打包的效率,也可以满足保护商业代码的需求。这里我们看看模块编译与发布的基本操作
3.4.1 如何编译模块
$ cd /path/to/module
1) 构建前端代码
$ npm run build:front
2) 构建后端代码
$ npm run build:backend
3.4.2 编译参数
- 前端编译:为了提升整体项目打包的效率,模块前端编译默认开启丑化处理
- 后端编译:默认关闭丑化处理,可通过修改编译参数开启丑化选项
后端为什么默认关闭丑化选项呢?
答:CabloyJS所有内置的核心模块都是关闭丑化选项的,这样便于您直观的调试整个系统的源代码,也可以很容易走进CabloyJS,发现一些更有趣的架构设计
{模块目录}/build/config.js
module.exports = {
productionSourceMap: true,
uglify: false,
};
3.4.3 模块发布
当项目中的模块代码稳定后,可以将模块公开发布,贡献到开源社区。也可以在公司内部建立npm私有仓库,然后把模块发布到私有仓库,形成公司资产,便于重复使用
$ cd /path/to/module
$ npm publish
4 业务开发
到目前为止,实话说,前面谈到的概念大多属于EggBornJS的层面。CabloyJS在EggBornJS的基础上,开发了大量核心业务模块,从而支持业务层面的快速开发。下面我们就介绍一些基本概念
4.1 原子的概念
4.1.1 原子是什么
原子是CabloyJS最基本的要素,如文章、公告、请假单,等等
为什么叫原子?在化学反应中,原子是最基本的粒子。在CabloyJS中,通过原子的组合,就可以实现任何想要的功能,如CMS、OA、CRM、ERP,等等
比如,您所看到的这篇文章就是一个原子
4.1.2 原子的意义
正由于从各种业务模型中抽象出来一个通用的原子概念,因而,CabloyJS为原子实现了许多通用的特性和功能,从而可以便利的为各类实际业务赋能
比如,模块CMS中的文章可以发表评论,可以点赞,支持草稿、搜索功能。这些都是CabloyJS核心模块egg-born-module-a-base-sync提供的通用特性与功能。只要新建一个原子类型,这些原子都会被赋能
这就是
抽象的力量
4.1.3 统一存储
所有原子数据都会有一些相同的字段属性,也会有与业务相关的字段属性。相同的字段都统一存储到数据表aAtom中,与业务相关的字段存储在具体的业务表中,aAtom与业务表是一对一的关系
这种存储机制体现了共性与差异性的有机统一,有如下好处:
- 可统一配置
数据权限 - 可统一支持
增删改查等操作 - 可统一支持
星标、标签、草稿、搜索等操作
关于原子的更多信息,请参见
4.2 角色体系
角色是面向业务系统开发最核心的功能之一,CabloyJS提供了既简洁又灵活的角色体系
4.2.1 角色模型
CabloyJS的角色体系不同于网上流行的RBAC模型
RBAC模型没有解决业务开发中资源范围授权的问题。比如,Mike是软件部的员工,只能查看自己的日志;Jone是软件部经理,可以查看本部门的日志;Jimmy是企业负责人,可以查看整个企业的日志
RBAC模型概念复杂,在实际应用中,又往往引入新的概念(用户组、部门、岗位等),使得角色体系叠床架屋,理解困难,维护繁琐
4.2.2 概念辨析
涉及到角色体系,往往会有这些概念:用户、用户组、角色、部门、岗位、授权对象等等
而CabloyJS设计的角色体系只有用户、角色、授权对象等概念,概念精简,层次清晰,灵活高效,既便于理解,又便于维护
1) 部门即角色
部门从本质上来说,其实就是角色,如:软件部、财务部等等
2) 岗位即角色
岗位从本质上来说,其实也就是角色,如:软件部经理、软件部设计岗、软件部开发岗等等
3) 资源范围即角色
资源范围也是角色。如:Jone是软件部经理,可以查看软件部的日志。其中,软件部就是资源范围
4.2.3 角色树
CabloyJS针对各类业务开发的需求,提炼了一套内置角色,并形成一个规范的角色树。实际开发中,可通过对角色树的扩充和调整,满足各类角色相关的需求
- root
- anonymous
- authenticated
- template
- registered
- activated
- superuser
- organization
- internal
- external
| 名称 | 说明 |
|---|---|
| root | 角色根节点,包含所有角色 |
| anonymous | 匿名角色,凡是没有登录的用户自动归入匿名角色 |
| authenticated | 认证角色 |
| template | 模版角色,可为模版角色配置一些基础的、通用的权限 |
| registered | 已注册角色 |
| activated | 已激活角色 |
| superuser | 超级用户角色,如用户root属于超级用户角色 |
| organization | 组织角色 |
| internal | 内部组织角色,如可添加软件部、财务部等子角色 |
| external | 外部组织角色,可为合作伙伴提供角色资源 |
4.3 API接口权限
CabloyJS是前后端分离的模式,对API接口权限的控制需求就提升到一个更高的水平。CabloyJS提供了一个非常自然直观的权限控制方式
比如模块egg-born-module-a-baseadmin有一个API接口role/children,是要查询某角色的子角色清单。这个API接口只允许管理员用户访问,我们可以这样做
4.3.1 功能与API接口的关系
我们把需要授权的对象抽象为功能。这样处理有一个好处:就是一个功能可以绑定1个或多个API接口。当我们对一个功能赋予了权限,也就对这一组绑定的API接口进行了访问控制
4.3.2 功能定义
先定义一个功能:role
egg-born-module-a-baseadmin/backend/src/meta.js
...
functions: {
role: {
title: 'Role Management',
},
},
...
4.3.3 功能绑定
再将功能与API接口绑定
egg-born-module-a-baseadmin/backend/src/routes.js
...
{ method: 'post', path: 'role/children', controller: role,
meta: { right: { type: 'function', name: 'role' } }
},
...
| 名称 | 说明 |
|---|---|
| right | 全局中间件right,默认处于开启状态,只需配置参数即可 |
| type | function: 判断功能授权 |
| name | 功能的名称 |
4.3.4 功能授权
接下来,我们就需要把功能role授权给角色superuser,而管理员用户归属于角色superuser,也就拥有了访问API接口role/children的权限
功能授权有两种途径:
- 调用API直接授权
- CabloyJS已经实现了功能授权的管理界面:用管理员身份登录系统,进入
工具>功能权限管理,进行授权配置即可
4.4 数据访问权限
前面谈到,针对各类业务数据,CabloyJS抽象出来原子的概念。对数据访问授权,也就是对原子授权
原子授权主要解决这类问题:谁能对哪个范围内的原子数据执行什么操作,基本格式如下:
| 角色 | 原子类型 | 原子指令 | 资源范围 |
|---|---|---|---|
| superuser | todo | read | 财务部 |
角色
superuser仅能读取财务部的todo数据
更详细信息,强烈建议参见
4.5 简单流程
在实际的业务开发中,难免会遇到一些流程需求。比如,CMS中的文章,在作者提交之后,可以转入审核员进行审核,审核通过之后方能发布
当原子数据进入流程时,在不同的节点,处于不同的状态(审核中、已发布),只能由指定的角色进行节点的操作
CabloyJS通过原子标记和原子指令的配合实现了一个简单的流程机制。也就是说,对于大多数简单流程场景,不需要复杂的流程引擎,就可以在CabloyJS中很轻松的实现
更详细信息,强烈建议参见
5 解决方案
前面说到CabloyJS研发经历了两个阶段:
- EggBornJS
- CabloyJS
如果说还有第三阶段的话,那就是解决方案阶段。EggBornJS构建了完整的NodeJS全栈开发体系,CabloyJS提供了大量面向业务开发的核心模块。那么,在EggBornJS和CabloyJS的基础上,接下来就可以针对不同的业务场景,研发相应的解决方案,解决实际的业务问题
5.1 Cabloy-CMS
CabloyJS是一个单页面、前后端分离的框架,而有些场景(如博客、社区等)更看重SEO、静态化
CabloyJS针对这类场景,专门开发了一个模块egg-born-module-a-cms,提供了一套文章静态渲染的机制。CabloyJS本身天然的成为CMS的后台管理系统,从而形成动静结合的特点,主要特性如下:
- 内置多站点、多语言支持
- 不同语言可单独设置主题
- 内置SEO优化,自动生成Sitemap文件
- 文章在线撰写、发布
- 文章发布时实时渲染静态页面,不必整站输出,提升整体性能
- 内置文章查看计数器
- 内置评论系统
- 内置全文检索
- 文章可添加附件
- 自动合并并最小化CSS和JS
- JS支持ES6语法,并在合并时自动Babel编译
- 首页图片延迟加载,自动匹配设备像素比
- 调试便捷
具体信息,请参见
5.2 Cabloy-Community
CabloyJS以CMS模块为基础,开发了一个社区模块egg-born-module-cms-sitecommunity,配置方式与CMS模块完全一样,只需选用不同的社区主题即可轻松搭建一个交流社区(论坛)
6 未来规划与社区建设
Atwood定律: 凡是可以用JavaScript来写的应用,最终都会用JavaScript来写
CabloyJS未来规划的核心之一,就是持续输出高质量的解决方案,为提升广大研发团队的开发效率不懈努力
CabloyJS以及所有核心模块均已开源,欢迎大家加入CabloyJS,发Issue,点Star,提PR,更希望您能开发更多的业务模块,共建CabloyJS的繁荣生态
7 名称由来
最后再来聊聊框架名称的由来
7.1 EggBornJS
这个名称的由来比较简单,因为有了Egg,所以就有了EggBorn。有一部动画片叫《天书奇谭》,里面的萌主就叫“蛋生”,我很喜欢看(不小心暴露了年龄😅)
7.2 CabloyJS
Cabloy来自蓝精灵的魔法咒语,只有拼对了Cabloy这个单词才会有神奇的效果。同样,CabloyJS是有关JS的魔法,基于模块的组合与生化反应,您将实现您想要的任何东西
8 结语
亲,您也可以拼对Cabloy吧!这可是神奇的魔法哟!

实话讲,没太看明白。
CabloyJS前端采用VueJS + Framework7 + WebPack,后端采用KoaJS + EggJS,数据库采用MySQL。
这样选型目的是啥?和egg的差异在哪里?
@i5ting
你的问题好,后续有机会我可以针对你提的问题再写篇文章。这里,先简要说一下:
1、EggJS主体上属于后端框架,本身提供了非常强大的功能和特性。CabloyJS以EggJS作为后端的基础,可以省下大量精力。此外,CabloyJS为了实现业务模块化,对EggJS的许多特性进行了扩展,比如模块变量隔离、模块后端编译打包等等,还有很多
2、CabloyJS前端选择Framework7是为了实现pc=mobile+pad的效果,因为Framework7内置的页面路由可以很自然的支持页面组件堆叠与回退,比vue-router好用。当然,Framework7界面风格也非常好看,特别是升级到V4后

