

一、方案背景
用户存储海量的文档、媒体文件等数据的同时,对文件元数据(Mate)的管理不可或缺。元数据拥有多维度的字段信息,基本信息包含文件大小、创建时间、用户等。随着人工智能的发展,通过AI技术提取文件核心要素也成为文件元数据的重要信息。以图片为例:用户通过智能媒体服务,获取分析图片核心标签并为标签打分,用户还可提取人脸识别相关信息,以及地理位置等信息,提取的信息也需要存储到文件元数据信息中。因而文件元数据的信息量不断增加,格式、类型也不断呈现多元化。
需求场景
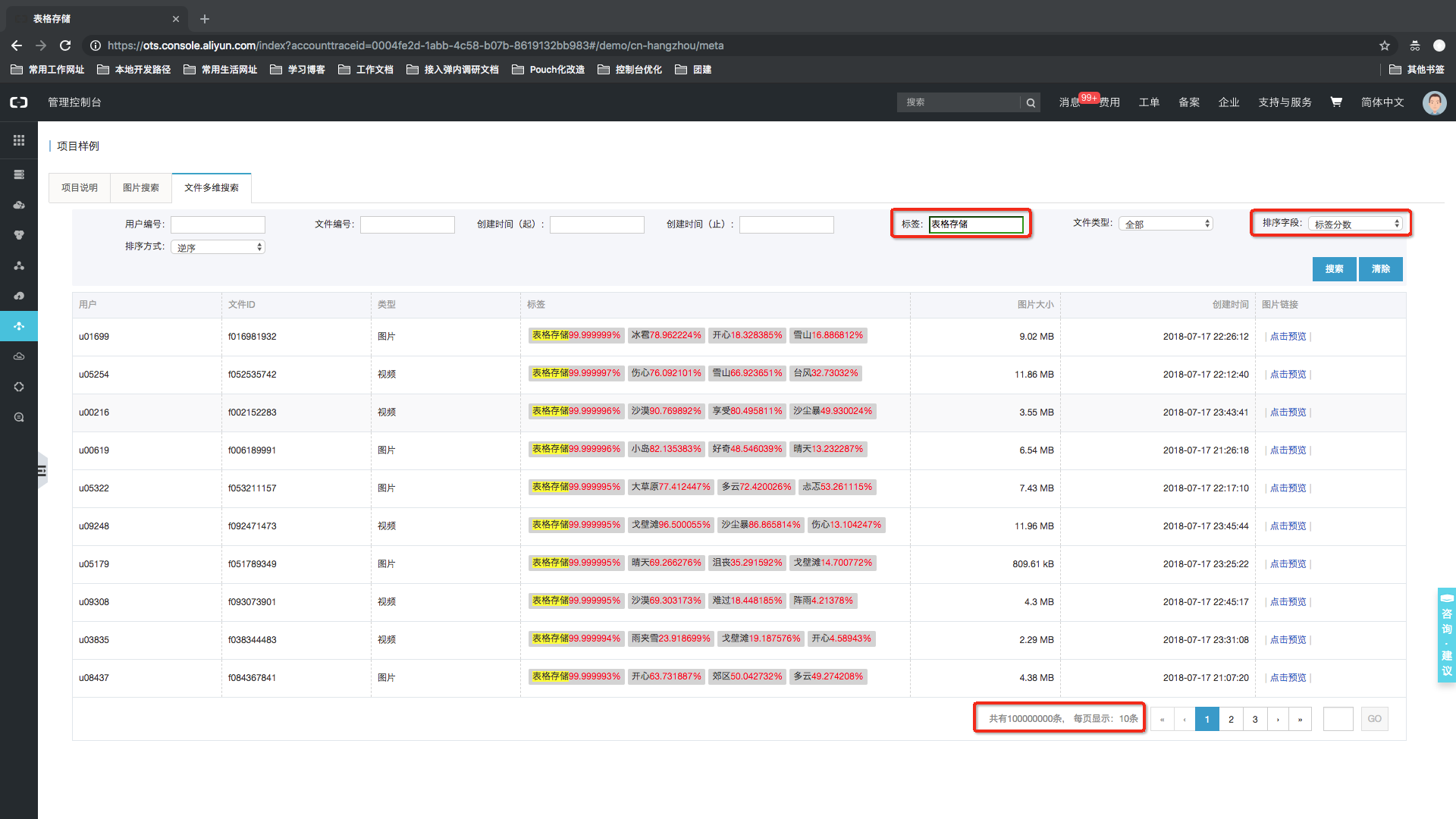
某智能媒体管理平台,为用户提供文件(图片、视频等)管理服务,用户通过自研(或售卖)的智能媒体分析工具,为目标文件进行分析。用分析后的信息丰富原有的元数据信息。因此,平台需要一套有效的元数据管理方案,为用户提供元数据信息的管理、分析、统计功能。例如: 用户A:【用户A的文件】*【近1年】*【标签含[开心]】*的所有图片,按标签分数排序 用户B:【用户B的文件】*【出现某某明星】*的所有视频,按明星相似度排序 … 管理系统样例,如下所示:官网控制台地址:项目样例
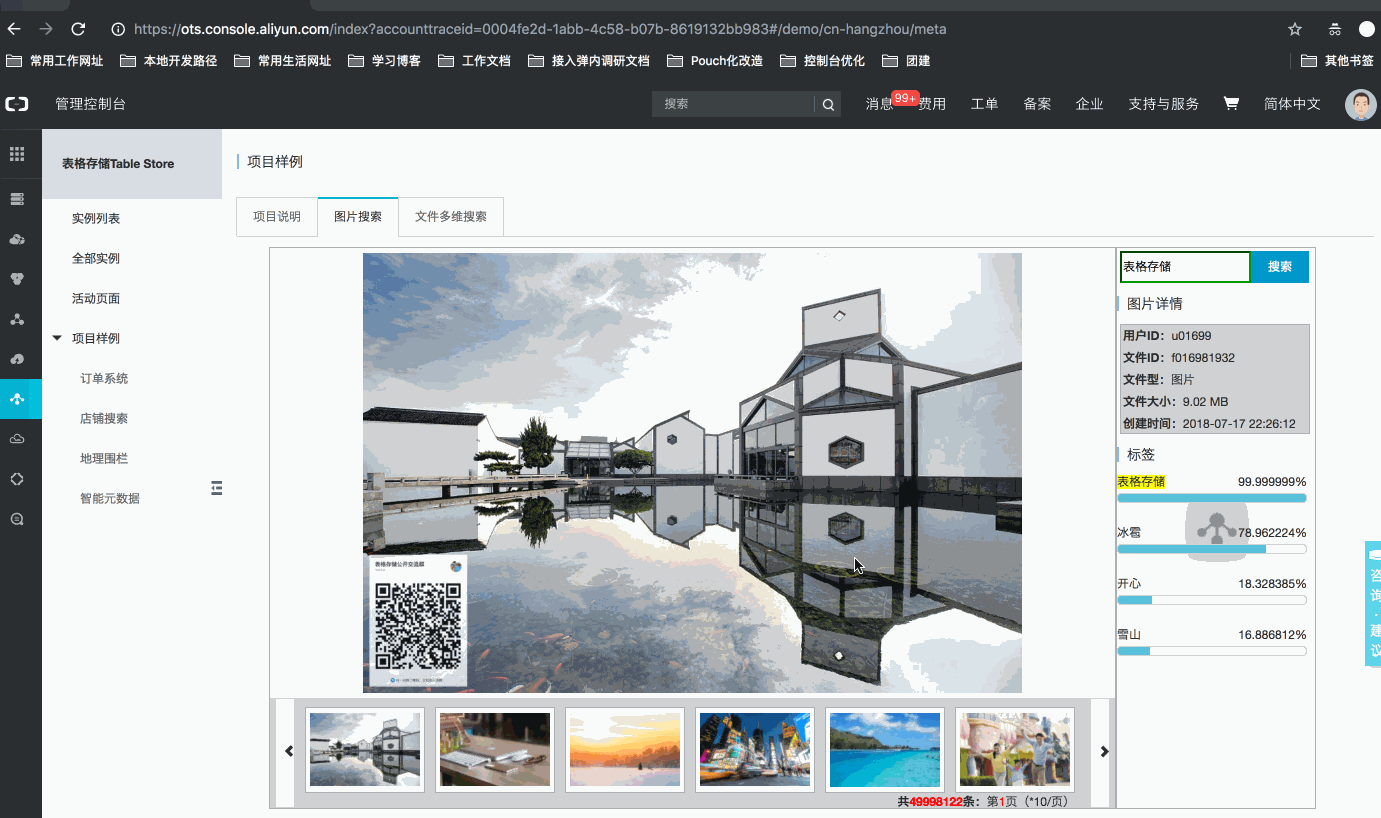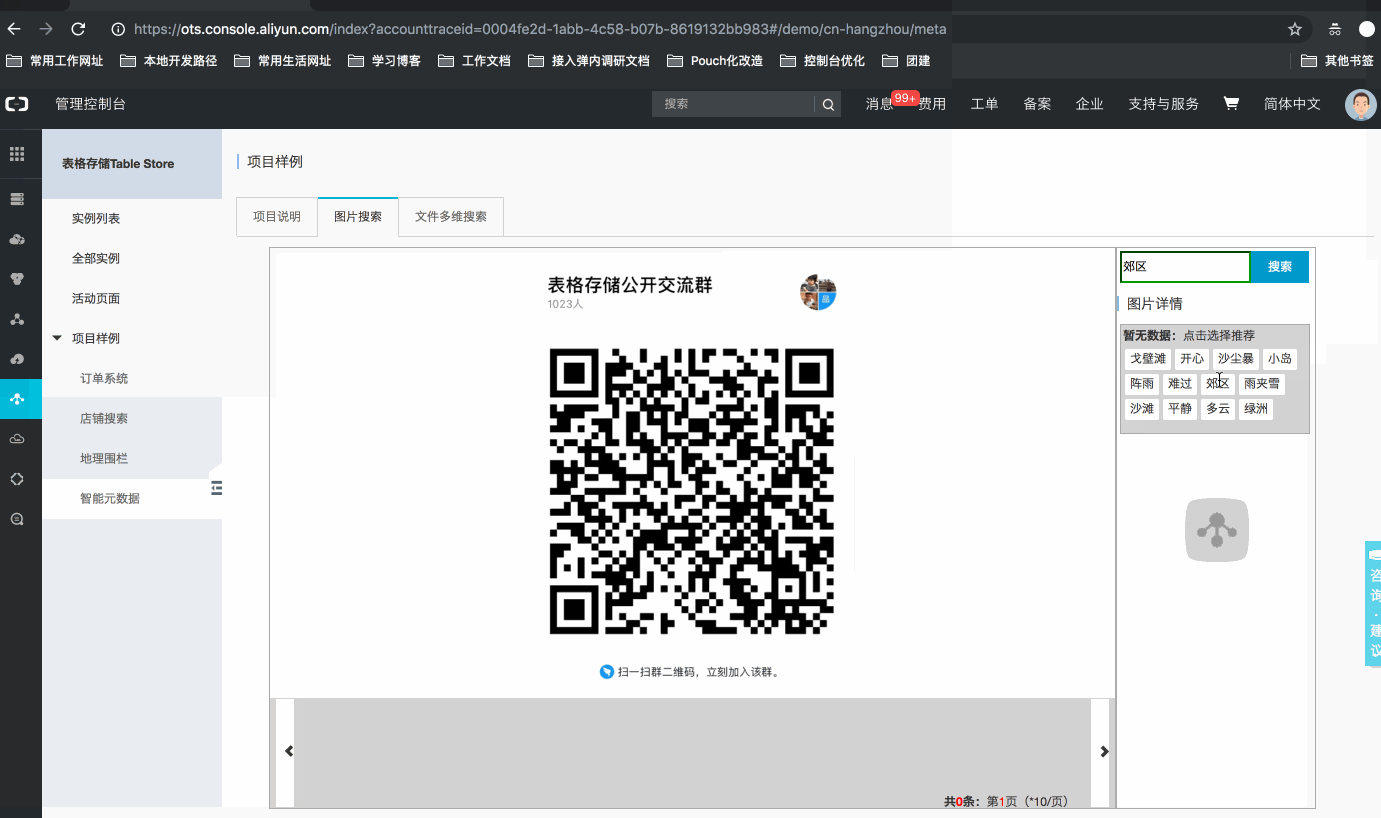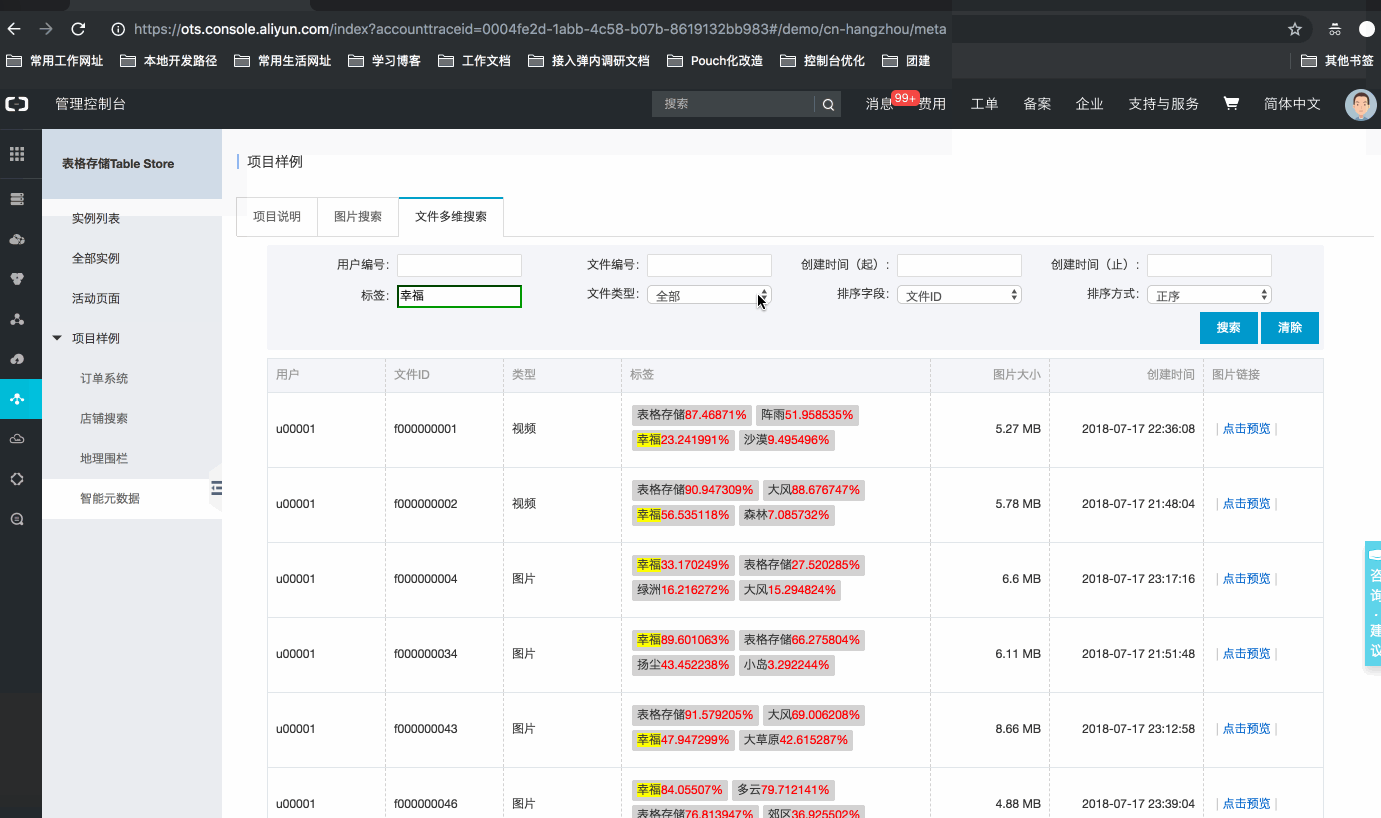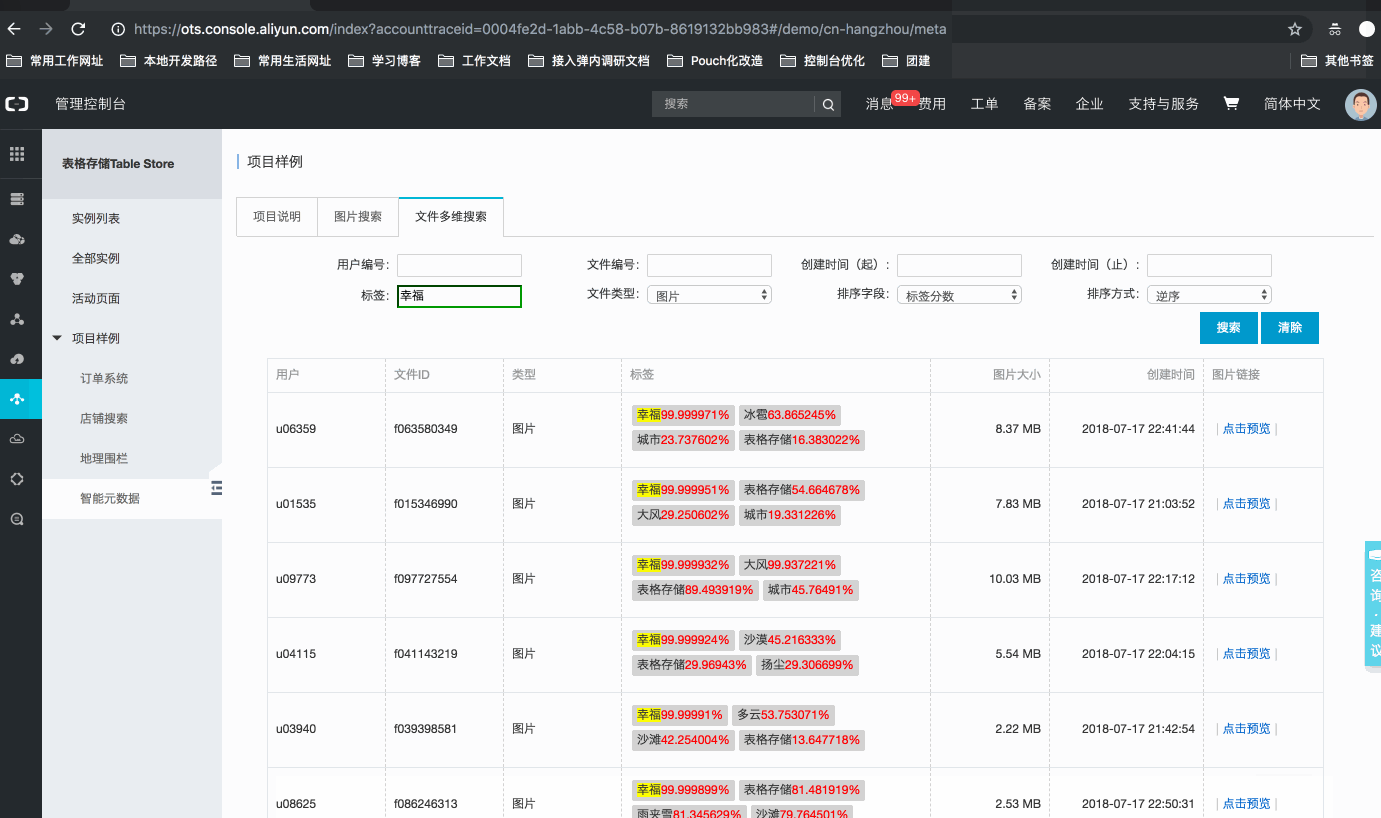
技术点
对于智能元数据管理系统,通常需要考虑的技术点,包含以下方面:
- 查询能力:具备强大的查询能力,如多类型索引、多维度组合查询等,同时具备排序、统计等功能;
- 横向扩展(多字段):元数据的字段类型丰富,字段变动、增删频繁,数据库尽量schema free来保证横向扩展能力;
- 纵向扩展(数据量):海量文件就会对应海量元数据,面对数据膨胀,数据库要满足易扩展、低成本等基本要求;
- 服务性能:应对高并发请的同时,保证低延迟、强一致、高可用;
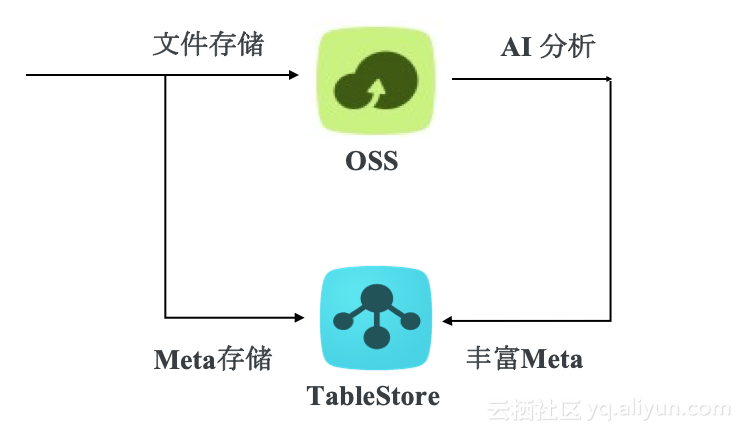
二、表格存储(TableStore)方案
使用表格存储(TableStore)研发的多元索引(SearchIndex)方案,可以有效解决海量元数据的管理问题。TableStore具有即开即用,按量收费等特点。 TableStore作为阿里云提供的一款全托管、分布式NoSql型数据存储服务,具有【海量数据存储】、【热点数据自动分片】、【海量数据多维检索】等功能,天然地解决了数据大爆炸这一挑战;在应对数据横向、纵向扩展上,充分发乎其优势。多元索引随时创建,是Meta元数据管理的合适方案。 同时,SearchIndex功能在保证用户数据高可用的基础上,提供了数据多维度搜索、统计等能力。针对多种场景创建多种索引,实现多种模式的检索。用户可以仅在需要的时候创建、开通索引。由TableStore来保证数据同步的一致性,这极大的降低了用户的方案设计、服务运维、代码开发等工作量。
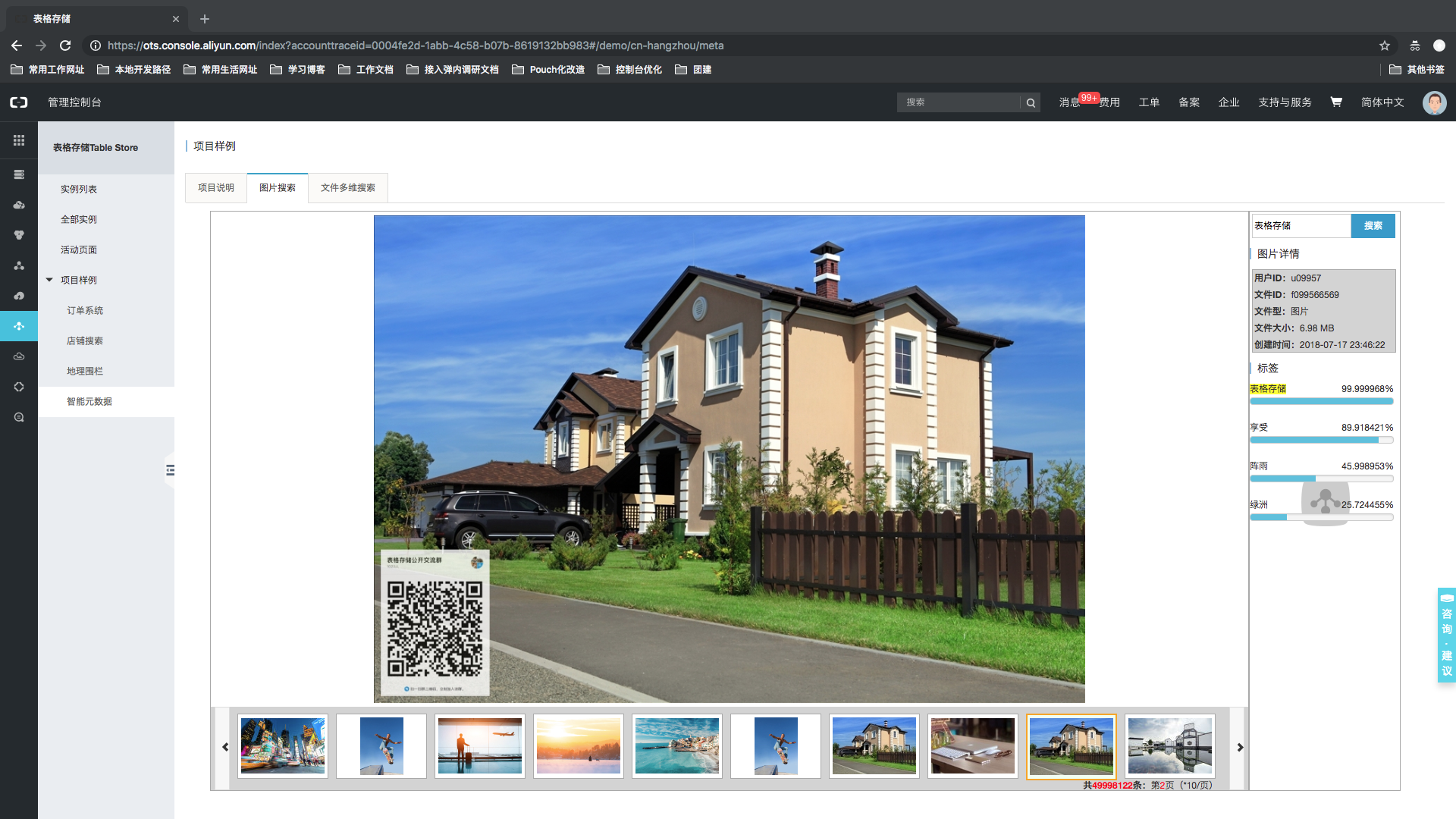
基于表格存储搭建的智能元数据管理系统页面一览
样例内嵌在表格存储控制台中,用户可登录控制台体验系统(若为表格存储的新用户,需要点击开通服务后体验,开通免费,Meta数据存储在公共实例中,体验不消耗用户存储、流量、Cu)。 注:该样例提供了【亿量级】文件元数据。官网控制台地址:项目样例
二、搭建准备
若您对于智能元数据管理系统感兴趣,希望开始自己系统的搭建之旅,只需按照如下步骤便可以着手搭建了:
1、开通表格存储
通过控制台开通表格存储服务,表格存储即开即用(后付费),采用按量付费方式,已为用户提供足够功能测试的免费额度。表格存储官网控制台、免费额度说明。
2、创建实例
通过控制台创建表格存储实例,选择支持多元索引的Region。(当前阶段SearchIndex功能尚未商业化,暂时开放北京,上海,杭州和深圳四地,其余地区将逐渐开放)
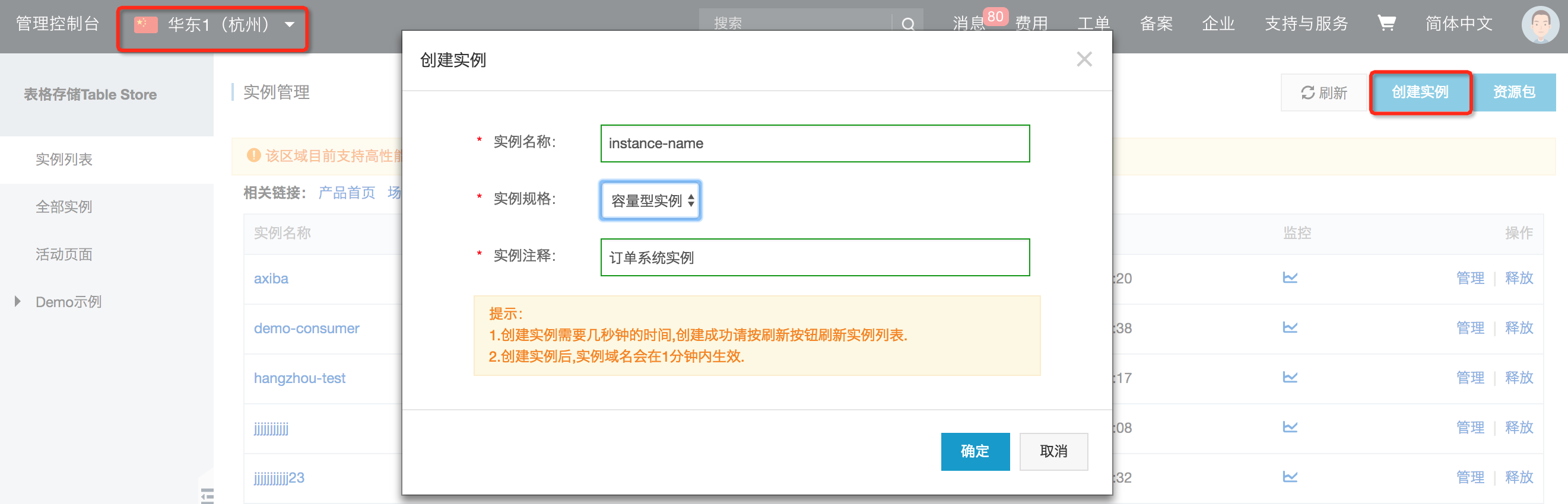
创建实例后,提交工单申请多元索引功能邀测(商业化后默认打开,不使用不收费)。
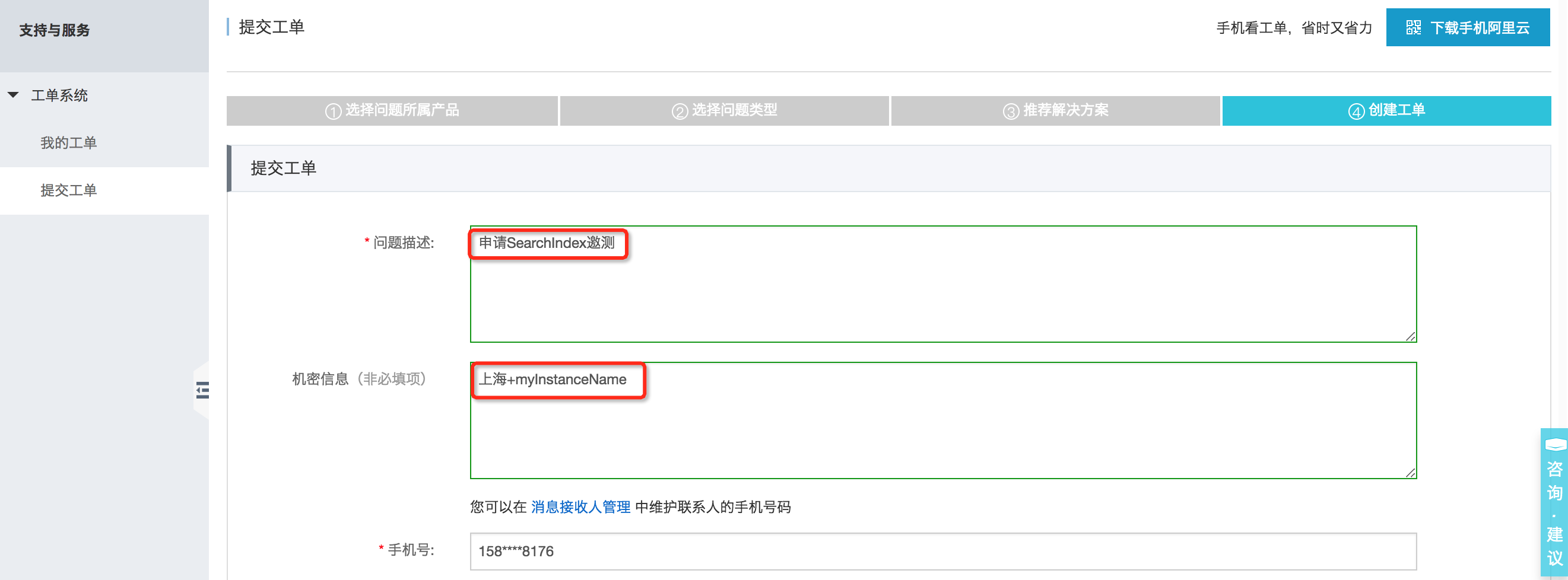
- 邀测地址:提工单,选择【表格存储】>【产品功能、特性咨询】>【创建工单】,申请内容如下:
- 问题描述:请填写【申请SearchIndex邀测】
- 机密信息:请填写【地域+实例名】,例:上海+myInstanceName
3、SDK下载
使用具有多元索引(SearchIndex)的SDK,官网地址,暂时java、go、node.js三种SDK增加了新功能
java-SDK
<dependency>
<groupId>com.aliyun.openservices</groupId>
<artifactId>tablestore</artifactId>
<version>4.8.0</version>
</dependency>
go-SDK
$ go get github.com/aliyun/aliyun-tablestore-go-sdk
Nodejs-SDK
$ npm install [email protected]
C#
$ Install-Package Aliyun.TableStore.SDK -Version 4.1.0
4、表设计
表名:order_contract
| 列名 | 数据类型 | 索引类型 | 字段说明 |
|---|---|---|---|
| _id(主键列) | String | MD5(oId)避免热点 | |
| fId | String | KEYWORD | 文件编号 |
| userId | String | KEYWORD | 用户编号 |
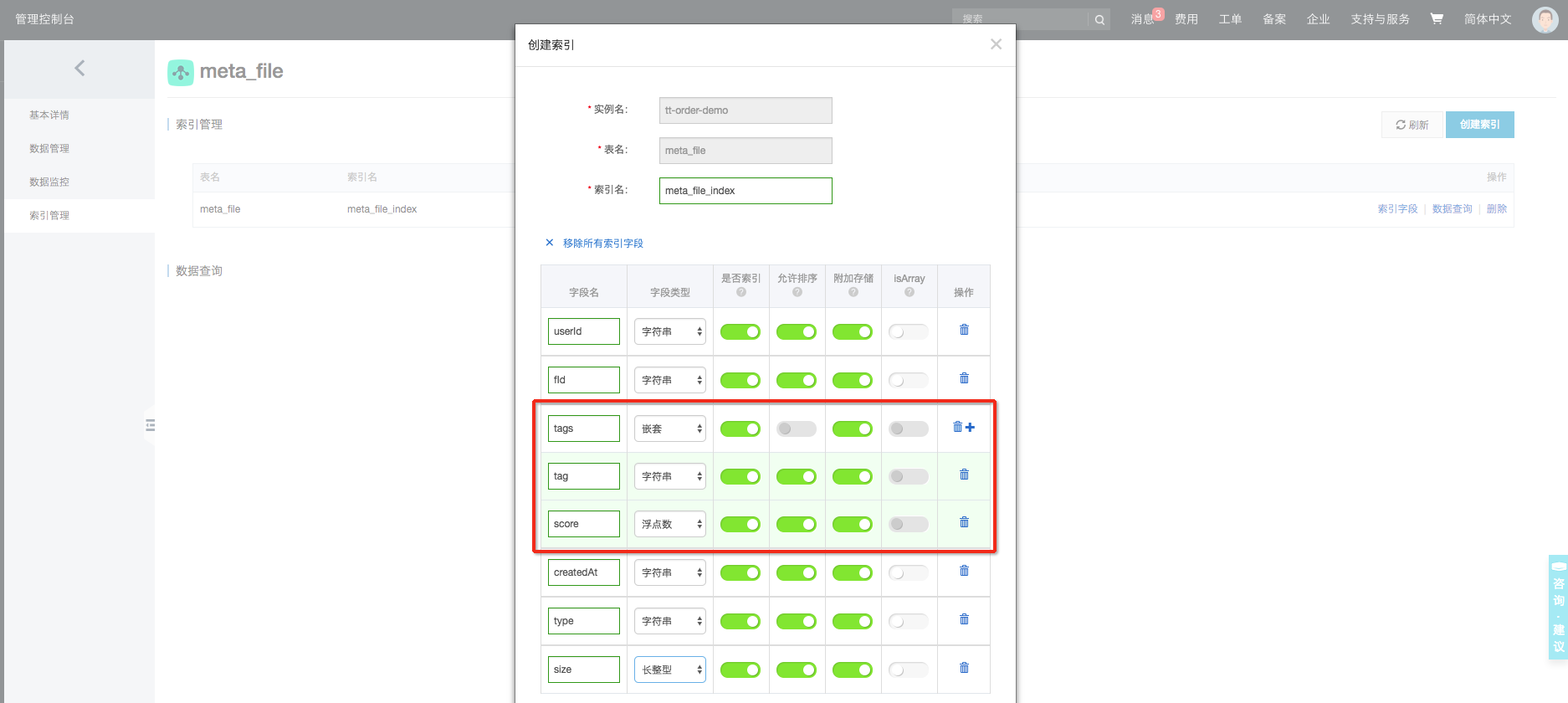
| tags | String | Nested: [{tag: String,score: LONG}] | 多标签使用嵌套索引(数组字符串) ‘[{“tag”:“表格存储”,“score”:97.317251},{“score”:50.770918,“tag”:“沙漠”}]’ |
| size | long | LONG | 文件大小 |
| createdAt | long | LONG | 创建时间(时间戳) |
| url | String | KEYWORD | 文件链接(存储于oss) |
| … | … | … | … |
三、开始搭建(核心代码)
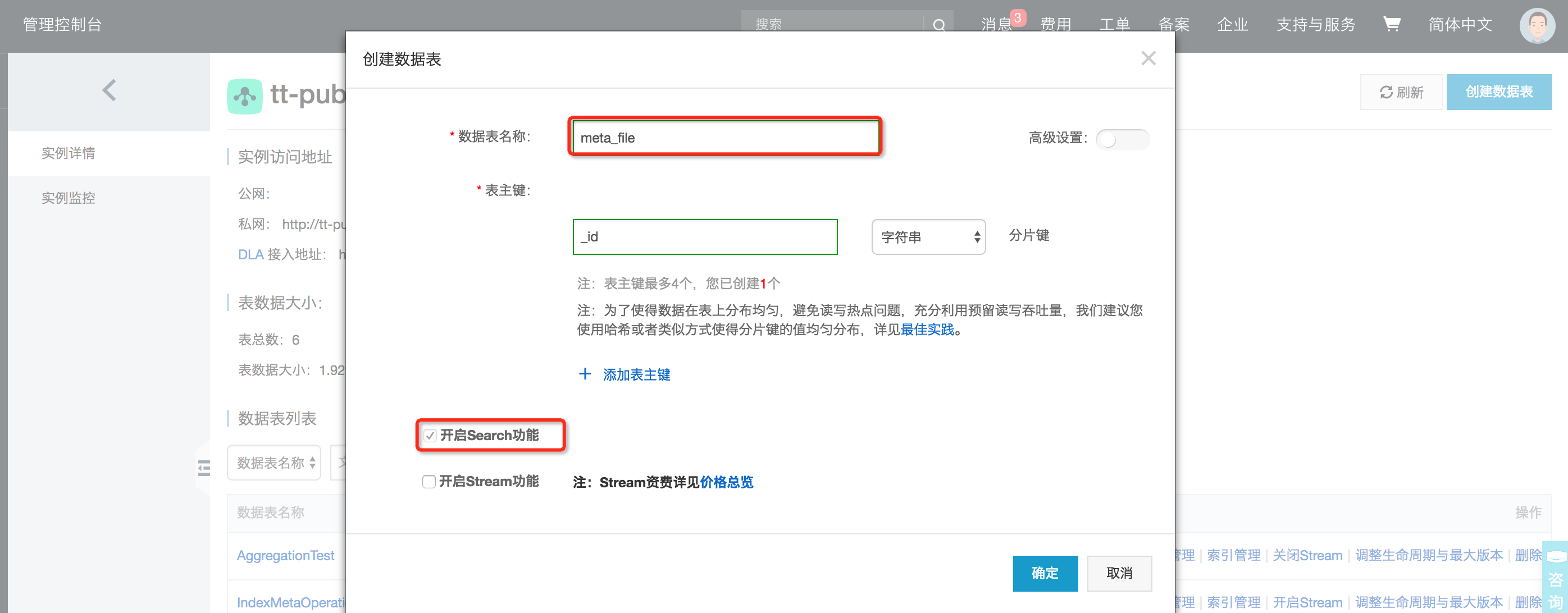
1、创建数据表
创建智能元数据表,用户仅需维护一个实例,按如下方式在实例下建表: 通过控制台创建、管理数据表(用户也可以通过SDK直接创建):
2、创建数据表索引 TableStore自动做全量、增量的索引数据同步:用户可以通过控制台创建、管理SearchIndex(用户也可通过SDK创建):
3、数据导入
插入部分测试数据(控制台样例中插入了1亿条数据,用户自己可以通过控制台插入少量测试数据);
| 文件编号 | 文件ID(md5主键) | 用户编号 | 标签(数组字符串) | 类型 | 链接 | 大小 |
|---|---|---|---|---|---|---|
| f052535742 | 1bce… | u05254 | [{“score”:99.999999,“tag”:“表格存储”},{“score”:78.962224,“tag”:“冰雹”},{“score”:18.328385,“tag”:“开心”},{“score”:16.886812,“tag”:“雪山”}] | “image” | 'https://prd-console-demo.oss-cn-hangzhou.aliyuncs.com/image/imm1.jpg | 9022066 |
4、数据读取
数据读取分为两类:
主键读取
基于原生表格存储的主键列获取:getRow, getRange, batchGetRow等。主键读取用于索引(自动)反查,用户也可以提供主键(文件编号md5)的单条查询的页面,亿量级下查询速度保持在十毫秒量级。单主键查询方式不支持多维度检索;
索引读取
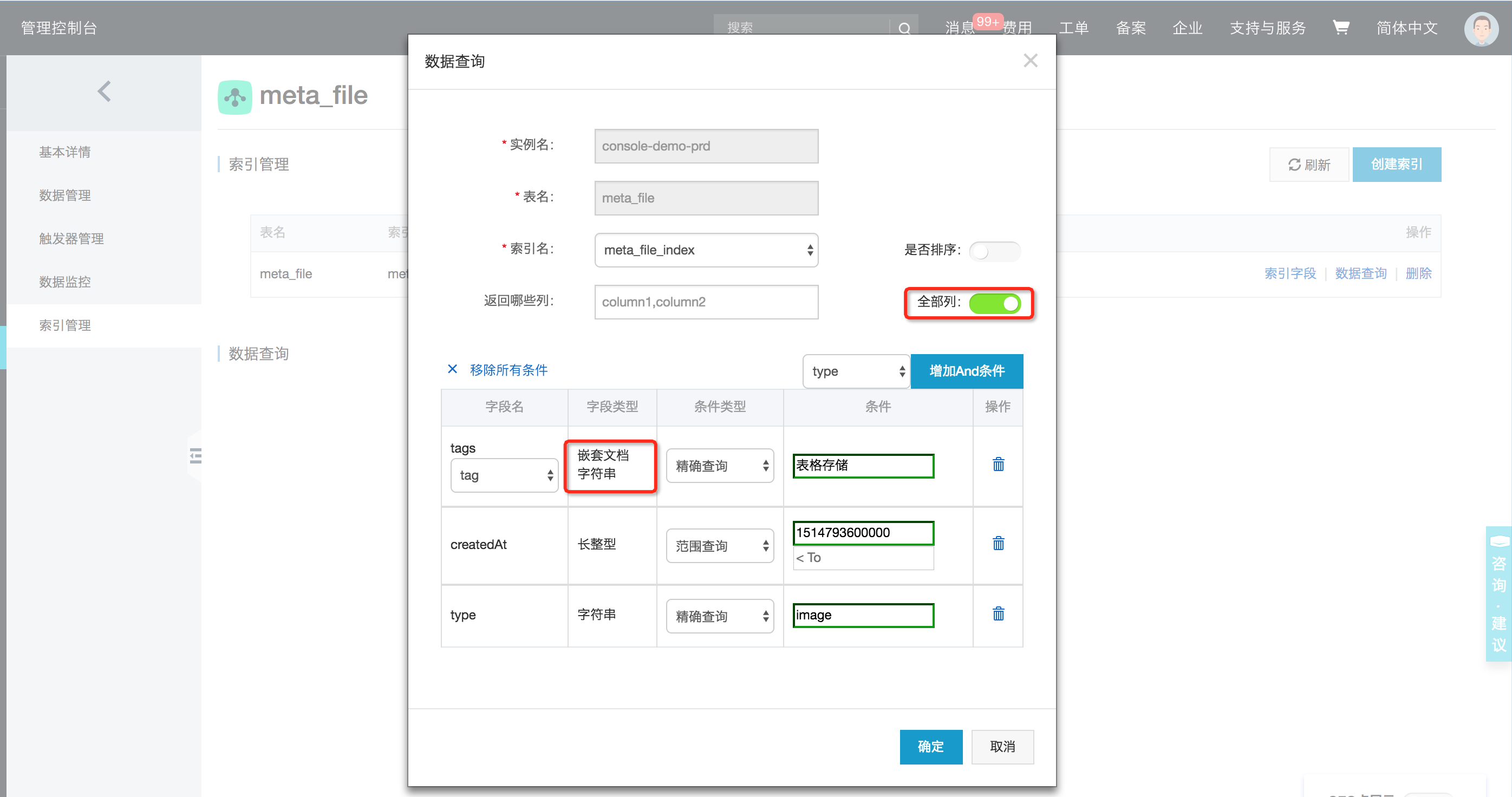
基于新SearchIndex功能Query:search接口。用户可以自由设计索引字段的多维度条件组合查询。通过设置选择不同的查询参数,构建不同的查询条件、不同排序方式;目前支持:精确查询、范围查询、前缀查询、匹配查询、通配符查询、短语匹配查询、分词字符串查询、嵌套查询、GEO查询,并通过布尔与、或组合。 如【标签为:表格存储,创建时间[2018-01-01, 2018-12-01)】文件的信息:(SDK与控制查询)
Node.js代码
client.search({
tableName: TABLE_NAME,
indexName: INDEX_NAME,
searchQuery: {
offset: 0,
limit: 10,
query: {
queryType: TableStore.QueryType.BOOL_QUERY,
query: {
mustQueries: [
{ //查询条件一:NesterdQuery,嵌套字段检索,标签为“表格存储”
queryType: TableStore.QueryType.NESTED_QUERY,
query: {
path: "tags",
query: {
queryType: TableStore.QueryType.TERM_QUERY,
query: {
fieldName: "tags.tag",
term: "表格存储"
}
},
}
},
{ //查询条件二:RangeQuery,创建时间大于1514793600000
queryType: TableStore.QueryType.RANGE_QUERY,
query: {
fieldName: "createdAt",
rangeFrom: 1514793600000,
}
},
{ //查询条件三:TermQuery,文件类型为图片"image"
queryType: TableStore.QueryType.TERM_QUERY,
query: {
fieldName: "type",
term: "image"
}
}
],
}
},
getTotalCount: true
},
columnToGet: {
returnType: TableStore.ColumnReturnType.RETURN_ALL
}
}, callback);
Java代码
List<Query> mustQueries = new ArrayList<Query>();
//嵌套字段Query
TermQuery termQuery = new TermQuery();
termQuery.setFieldName("tags.tag");
termQuery.setTerm(ColumnValue.fromString("表格存储"));
NestedQuery nestedQuery = new NestedQuery();
nestedQuery.setPath("tags");
nestedQuery.setScoreMode(ScoreMode.Avg);
nestedQuery.setQuery(termQuery);
mustQueries.add(nestedQuery);
//范围Query
RangeQuery rangeQuery = new RangeQuery();
rangeQuery.setFieldName("createdAt");
rangeQuery.setFrom(ColumnValue.fromLong(1514793600000, true);
rangeQuery.setTo(ColumnValue.fromLong(1543651200000, false);
mustQueries.add(rangeQuery);
//精确Query
TermQuery termQuery = new TermQuery();
termQuery.setFieldName("type");
termQuery.setTerm(ColumnValue.fromString("image"));
mustQueries.add(termQuery);
BoolQuery boolQuery = new BoolQuery();
boolQuery.setMustQueries(mustQueries);
四、欢迎加入
__引自云栖:原文地址:https://yq.aliyun.com/articles/673797
这样,系统的核心代码已经完成,基于表格存储搭建智能元数据管理系统,是不是很简单? 对表格存储(TableStore)感兴趣的用户,欢迎加入【表格存储公开交流群】,群号:11789671。

{kind=link}
去年九月开始用了一段时间,配合serverless用的,很多功能都是开发或者测试中,符合它场景的时候很好用,不在预设的应用场景下就很难受。后面更新的sql查询和索引功能,解决了不少问题,倒是方便了好多。不过当时看表格存储的文章和群里大佬直播啥的还是学到了很多。 总体下来,就是感觉node的方面的支持要比java方面的支持差了不少,基本都是java的文档和sdk之类的最全,每次参考都去看java的
@xiaoxiaoking Serverless场景紧密结合,您走在了前面! 新上线的索引功能,目前已经商业化,检索的能力有了大幅提升。 您提到的node支持,后续也会不断增加