

本文首次发表于北斗同构github, 转载请注明出处
注: 本文为第12届D2前端技术论坛《打造高可靠与高性能的React同构解决方案》分享内容,已经过数据脱敏处理。
前言
很多前端工程师在做页面性能调优的过程中,极少关注代码本身的执行效率,更多关注的是网络消耗,比如资源合并减少请求数、压缩降低资源大小、缓存等. 我并不觉得这不合理,相反,在很大程度上这是足够正确的做法,举个例子, JS本身的执行时间是30ms(毫秒),在动辄三五秒的页面加载时间中的占比实在太低了,就算拼了命把性能提升10倍,执行时间降到3ms,整体性能提升也微不足道,甚至在用户层面都无法感知. 因此去优化其它性能消耗的大头更加明智.
但从Node.js(服务端)的角度来看,JS本身的执行时间却变得至关重要,还是之前的例子,如果执行时间从30ms降到3ms, 理论上QPS就能提升10倍,换句话说,以前要10台服务器才能扛住的流量现在1台服务器就能扛住,而且响应时间更短.
那到底Node端如何做性能优化呢?
方法
有两种方法,一种是通过Node/V8自带的profile能力 , 另一种是通过alinode的 CPU profile功能. 前者只列出了各函数的执行占比, 后者包括更加完整的调用栈,可读性更强,更加容易定位问题,建议采用后者.
方法1: Node 自带 profile
- 第1步: 以–prof参数启动Node应用
$ node --prof index.js
- 第2步: 通过压测工具loadtest向服务施压
$ loadtest http://127.0.0.1:6001 --rps 10
- 第3步: 处理生成的log文件
$ node --prof-process isolate-0XXXXXXXXXXX-v8-XXXX.log > profile.txt
- 第4步: 分析profile.txt文件
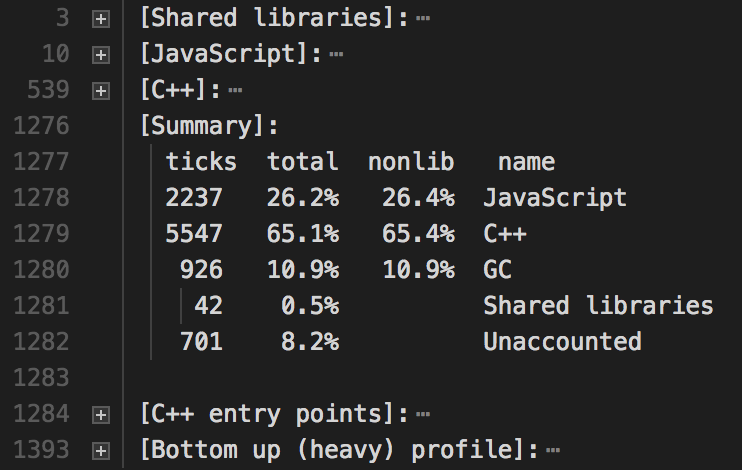
profile.txt文件如下图,包括JS和C++代码各消耗多少ticks, 具体分析方法详见node profile文档
方法2: alinode的CPU profile
- 第1步: 安装alinode
alinode是与 Node 社区版完全兼容的二进制运行时环境, 推荐使用tnvm工具进行安装
$ wget -O- https://raw.githubusercontent.com/aliyun-node/tnvm/master/install.sh | bash
完成安装后,需要将tnvm添加为命令行程序. 根据平台的不同,可能是~/.bashrc,~/.profile 或 ~/.zshrc等
$ source ~/.zshrc
以alinode-v3.8.0为例, 对应node-v8.9.0, 下载该版本并启用它
$ tnvm install alinode-v3.8.0
$ tnvm use alinode-v3.8.0
- 第2步: 用安装的alinode运行时启动应用
$ node --perf-basic-prof-only-functions index.js
- 第3步: 通过压测工具loadtest向服务施压
$ loadtest http://127.0.0.1:6001 --rps 10
- 第4步: cpu profile
假设启动的worker进程号为6989, 执行以下脚本, 三分钟后将在/tmp/目录下生成一个cpuprofile文件/tmp/cpu-profile-6989-XXX.cpuprofile
脚本详见take_cpu_profile.sh
$ sh take_cpu_profile.sh 6989
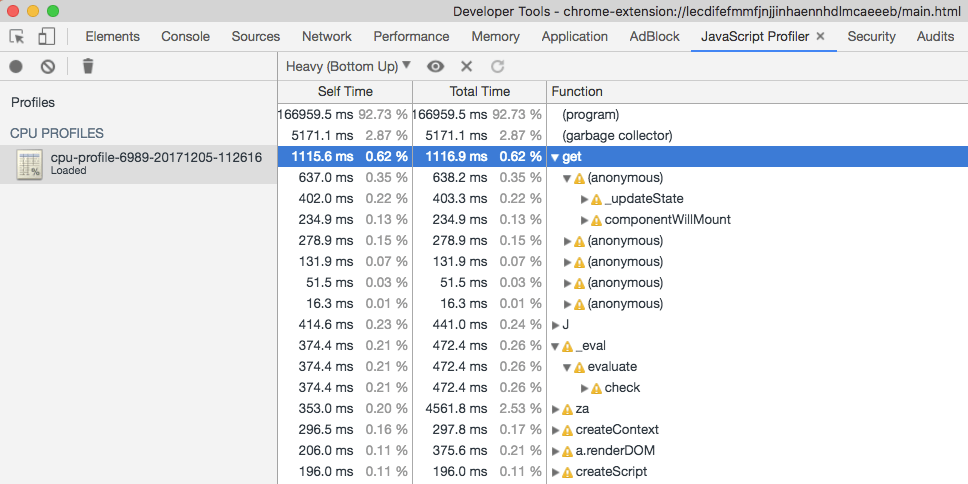
- 第5步: 将生成的cpuprofile文件导入到Chrome Developer Tools进行分析
实战
下面通过一个真实的案例展示如何一步步地做性能调优.
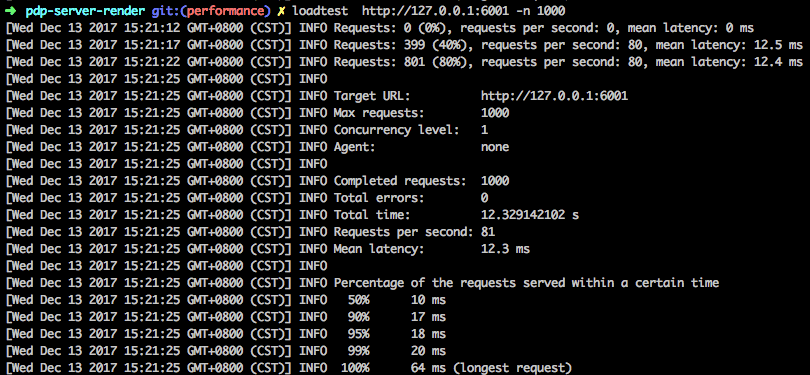
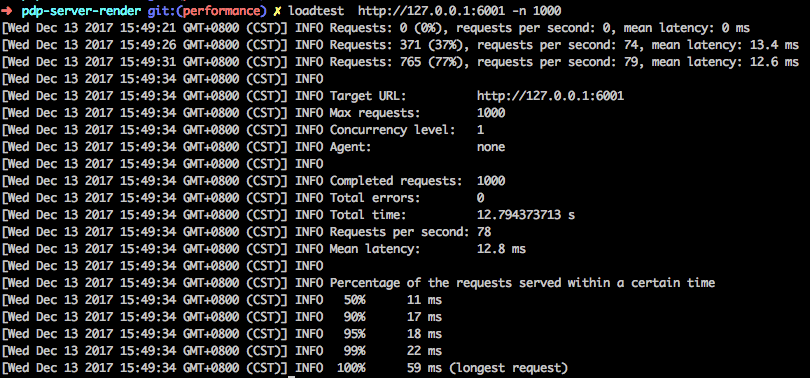
通过loadtest请求1000次,统计平均RT, 初始RT为15.8ms

剔除program和GC消耗,性能消耗的前三位分别是get,J和_eval三个方法
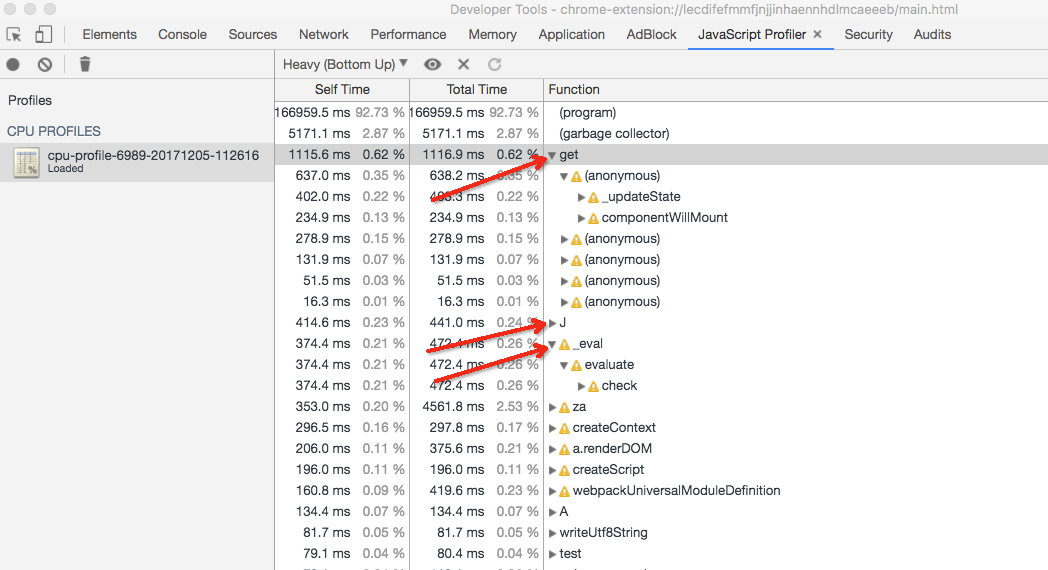
展开最耗性能的get方法调用栈,可以定位到get方法所在的位置,具体代码如下
{
key: 'get',
value: function get(propName) {
if (!this.state[propName]) {
return null;
}
return JSON.parse(JSON.stringify(this.state[propName]));
}
}
方法体中,JSON.parse(JSON.stringify(obj))虽然使用便捷,但却是CPU密集型操作. 做一次验证,去除该操作, 直接返回this.state[propName]. RT时间降为12.3ms了
这仅仅是一次试验,肯定不能直接移除JSON.parse(JSON.stringify(obj)), 不然会影响业务逻辑的. 参考下常用拷贝方法的性能对比, 自配梯子. 截图如下:
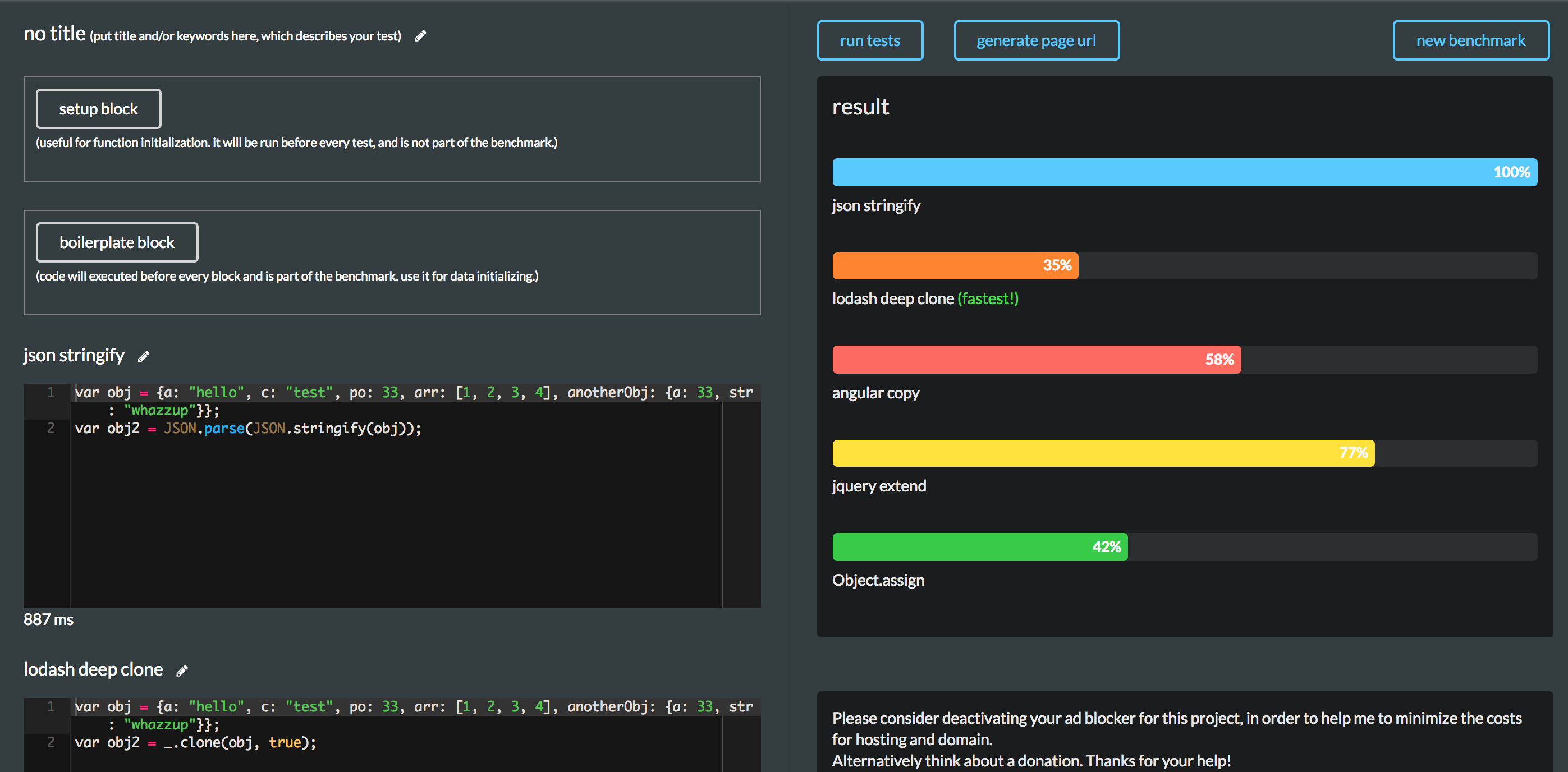
其中性能最优的是lodash deep clone,采用该库替换,再验证一遍, RT降为12.8ms
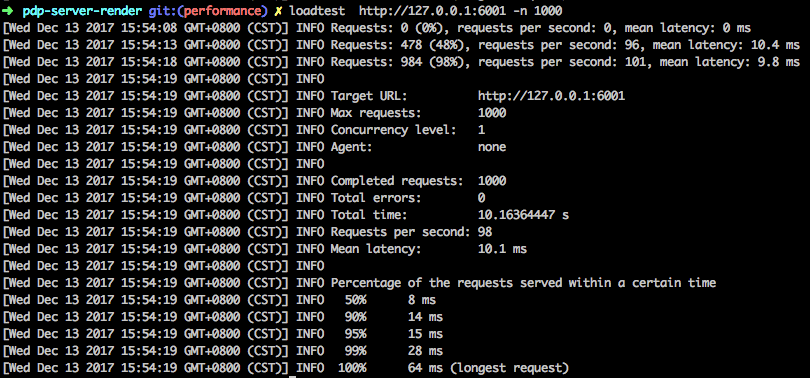
第二耗性能是的J方法,里面大部分是各个组件的render时间,暂时略过,以同样的方式对_eval方法进行一次优化, RT降为10.1ms.
以此类推,根据CPU profile找出性能消耗的点,逐个去优化.

@yakczh 看场景吧,正常情况下,nodejs已经足够快了,但某些场景下还是需要去做性能优化的,比如SSR,CPU密集型的,对内存要求不高。还有看并发量吧



