

最近我找工作进度缓慢,有意向的公司屈指可数,看着朋友圈里面天天晒“我很忙”的 hr,感慨当年拉钩论坛上可以扔出自己的简历,让有意向的公司找到自己,而现在没有拉勾论坛了,各公司的招聘的描述大同小异,很难看出谁就是我要的。
因为我之前是研发自动化测试工具的,日站无数,为什么不研究自动投递简历呢?如果你正在看这篇文章,说明你和我一样找工作困难,希望这里的自动化的思想和脚本能帮到你。
在开始之前多唠叨一句,日站有一点非常关键,就是 CSS 选择器,如果你不熟悉,可以使用火狐的 “复制 css 选择器”功能。如图:
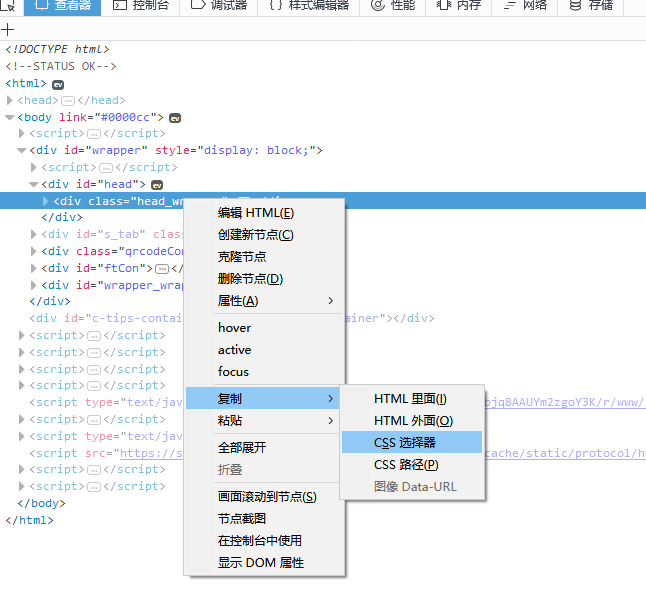
很多地方的参数都要填选择器,至于为什么那么填,大约要么是经验,要么我也是用工具选的。 (我知道 Chrome 也有这个功能,但是火狐的算法更好)
不想看我废话 ,项目在这里
1.拉勾
拉勾是一家专业的互联网招聘网站。从我接到过Boss直聘的电话来看,它们对竞争对手爬页面都没啥防备,所以自动投递应该可行。
第一步肯定是下载 puppeteer, 运行 yarn add puppeteer,结果失败了,尽管我开了蓝灯。
我只好曲线救国,手动下载 Chrome Canary,然后根据文档
的说法,在.npmrc里面加入一句PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true禁止自动下载 Chromium。如果你有好的 VPN 或者 SS 直接自动拉应该就可以吧。
搞定了下载之后,可以先 Hello World 试试:
const puppeteer = require('puppeteer');
const main = async () => {
const browser = await puppeteer.launch({
headless: false,
slowMo: 250,
executablePath: "C:\\Users\\Admin\\AppData\\Local\\Google\\Chrome SxS\\Application\\chrome.exe"
});
const page = await browser.newPage();
await page.goto('https://www.lagou.com/');
page.on('console', msg => console.log('PAGE LOG:', ...msg.args));
await page.evaluate(() => console.log(`url is ${location.href}`));
await browser.close();
};
main().catch(console.error);
首先我有一个入口的 main 异步函数,调用并 catch,防止 node 抱怨 Promise 没有抓错。
puppeteer.launch 那里,headless 是是否以无头模式启动,当然选否,为了调试方便,slowMo 是动作间隔,executablePath 指向的是我下载的 Chrome Canary 的位置。
之后的代码就是打开新的选项卡,浏览拉勾首页,Console 当前连接,并退出,没啥可说的。
第二步计划是登录自己的账户,然后浏览职位列表。 为了在不泄露自己的用户名和密码的情况下和诸位分享代码,肯定要使用 dotenv 这样的配置工具,部署过 node 服务器的应该对它不陌生吧。
所以我在文件的第一行加上 require('dotenv').config();
之后当然是直接访问拉勾的登录页面,输入用户名和密码,点击登录。
await page.goto('https://passport.lagou.com/login/login.html');
// 用户名
await page.type('form.active > div:nth-child(1) > input:nth-child(1)', process.env.lagou_name);
// 密码
await page.type('form.active > div:nth-child(2) > input:nth-child(1)', process.env.lagou_pass);
// 登录按钮
await page.click('form.active > div:nth-child(5) > input:nth-child(1)');
await page.waitForNavigation();
// 直接跳转
await page.goto('https://www.lagou.com/zhaopin/webqianduan/?labelWords=label');
const title = await page.title();
console.log(title);
这里 page.type 方法是输入文字。而 process.env.lagou_name 自然是从 .env 的配置里面来的。
点击了登录按钮之后,页面会跳转,所以用 page.waitForNavigation() 来等待登录的跳转。
登录跳转成功之后,肯定是要进对应的页面,但是这里不需要我们模拟点击那些 Node.js 或 web 前端,因为那些只是普通的 a 标签的链接而已。我只需要再次浏览到对应的页面即可。
进入职位列表之后,我一般会选择城市,并且按照更新时间排序,此时拉勾会刷新页面,链接是类似这样的: https://www.lagou.com/jobs/list_web前端?px=new&city=天津#order
看来得引用 querystring 才能让跳转参数化了,const {escape} = require('querystring');。然后链接改为:
await page.goto(`https://www.lagou.com/jobs/list_${escape('web前端')}?px=new&city=${escape('天津')}#order`);
第三步肯定是自动投递。我们可以到处看一看,心中有个底,决定好了要投哪几家再行动。但是那样的程序还不好一下写出,当下简单粗暴的方法是:
获取职位列表的第1页的15个职位,对职位进行一定过滤,选择剩下的职位的第1个进行投递。投递完之后拉勾会自动过滤掉你投递过的,如此反复即可。
所以:
const jobs = await page.$$eval('#s_position_list > ul > li', positionList =>
positionList.map(function mapPosition(position) {
const dataset = position.dataset;
const [salary1, salary2] = dataset.salary.split('-');
return {
title: dataset.positionname.toLowerCase(),
company: dataset.company.toLowerCase(),
salaryLo: parseInt(salary1),
salaryHi: parseInt(salary2),
id: parseInt(dataset.positionid)
};
})
);
page.$ 是在页面执行 document.querySelector, page.$$ 是在页面执行 document.querySelectorAll,这2个 api 还对应一个 eval 就是可以有一个回调来过滤数据啦。换句话说,page.$$eval 就是执行 document.querySelectorAll,并对执行结果进行处理。
拉勾的前端用的 jQuery 时代把数据写在 DOM 的 dataset 属性上的套路,所以获取 DOM 列表之后,直接拿出对应数据:
- positionname:工作名称。投前端需要过滤 Java web。
- company:公司名。可以用来过滤不友好和正在谈的目标。
- salary:薪水。这个数据需要稍微处理一下,方便之后过滤。
- positionid:这个是投简历页面的链接的一部分。
因此:
function getJobLink(jobs) {
const goodJobs = jobs.filter(function(job) {
if (job.title.indexOf('java') > -1) {
return false;
}
// 其它过滤条件
return true;
});
if (goodJobs.length > 0) {
const job = goodJobs[0];
return `https://www.lagou.com/jobs/${job.id}.html`;
}
return null;
}
这里你可以有自己的薪水,公司黑名单等过滤条件。我们过滤完之后,拿剩下的第一工作,拼成投递页面的链接。
const jobLink = getJobLink(jobs);
//console.log(jobLink);
await page.goto(jobLink);
await page.click('.fr.btn_apply');
获取一个可以投递的链接,跳转到该链接上,并且点击投递。。。
这时会有至少两种情况,一种是拉勾ok了,你可以点击“我知道了”。另一种是拉勾说我写的经验年限不够,是否确认。我是要投现代前端和Node的,就连创始人也就8年经验,所以我当然要忽略那些要5-10年经验的智障要求。
await page.click('#delayConfirmDeliver').catch(() => {});
await page.click('#knowed').catch(() => {});
await page.waitForNavigation();
这里的意思是,点击“确认投递”,如果没有该按钮,不要挂掉。点击“我知道了”,如果没有,不要挂掉。最后等待页面刷新。
此时已经可以自动投递了,只需要润色一下,让它可以不断自动投递到拉勾的投递上限即可。
2.智联
智联招聘的界面很乱,尤其是最近由乱入了些现代互联网风格的页面,让人感觉很糟糕,我也不常用。
智联上骗子公司和培训公司似乎比较多,所以只做自动更新简历,不要投递。
话说这智联真是一个神奇的网站,有的地方登录要验证码,有的地方又不需要。。。
所以第一点就是必须从百度搜索的链接进入页面,这样没有验证码,地址是: http://ts.zhaopin.com/jump/index_new.html?sid=121113803&site=pzzhubiaoti1
代码上的话,就只有一点比较神奇,就是如果登录后的弹窗不关掉,页面上的 a 标签居然不可点。
await page.click('.Delivery_success_popdiv_title span.fr').catch(() => {});
await page.click('.amendBtn');
await page.waitForNavigation();
所以这里就点击那个 x,不管成不成功,继续点击修改简历,等待跳转。之前的登录和之后的点刷新的代码详见 zhilian/index.js 文件
3.100offer
100offer自称是“让最好的人才遇见更好的机会”的一个招聘网站。
这个网站和别的长的不太一样,你点城市或者下一页是,它的页面会有 Ajax 请求,返回结果只有一个字段:html,然后它会把这段 html 用 jQuery 插入到 DOM 树中,真是神奇。
所以前面登陆和跳转页面自然没啥说的:
const page = await browser.newPage();
await page.goto('https://cn.100offer.com/signin');
// 用户名
await page.type(
'#talent_email',
process.env.o100_name
);
// 密码
await page.type(
'#talent_password',
process.env.o100_pass
);
// 登录按钮
await page.click('#new_talent > div:nth-child(6) > input:nth-child(1)');
await page.waitForNavigation();
// 直接跳转
await page.goto('https://cn.100offer.com/job_positions');
// 帝都
await page.click('.locations.filters > div:nth-child(3)');
// 不要求学历
await page.click('.degree.filters > div:nth-child(7)');
现在的情况很微妙,因为100offer不能按照职位关键字来过滤,所以页面上有很多不相干的 Java 职位。
所以重点来了:
async function getJobLink() {
const jobs = await page.$$eval('.position-list > .position-item a.h3-font', links =>
links.map(function mapLinks(link) {
return {
name: link.text.toLowerCase(),
url: link.href
};
})
);
const goodJobs = jobs.filter(function (job) {
if (job.name.indexOf('Node') > 0) {
return true;
}
if (job.name.indexOf('前端') > 0) {
return true;
}
return false;
});
if (goodJobs.length > 0) {
return goodJobs[0].url;
}
// 翻页
const nextEl = await page.$('a.next');
if (nextEl == null) {
return null;
}
await nextEl.click();
return await getJobLink();
}
这个 getJobLink 是个递归函数,递归搜索职位。
首先,在页面中抓取所有职位的名称和链接。对职位名称过滤,比如我只要 Node 和 前端。
如果没有找到,这时就需要翻页了。先查有没有下一页这个元素const nextEl = await page.$('a.next'); 如果不可以点下一页,那自然查找失败。如果有,当然是点击下一页,然后递归搜索。
之后的点击投递,忽略警告和拉钩类似,我就不再贴出来。代码在项目的 100 文件夹下
4.社区
很多时候,我也会在社区里面看一些机会,但是天天都是重复那几个动作:
打开社区a,b,c,点击招聘板块,看看最新的帖子。
为什么不让看帖自动化呢?
我只会 JS 和 Go,Go 语言更适合这个工作,况且我出差用的小米笔记本都有2核4线程,不利用一下真是太傻了。
首先是 main 函数
func main() {
results := make(chan *Result)
var wg sync.WaitGroup
wg.Add(len(sites))
for _, site := range sites {
matcher, ok := matchers[site.resType]
if !ok {
matcher = matchers["default"]
}
go func(matcher Matcher, url string) {
err := doMatch(matcher, url, results)
if err != nil {
log.Println(err)
}
wg.Done()
}(matcher, site.url)
}
go func() {
wg.Wait()
close(results)
}()
display(results)
}
如果你不会 Go 的话,这里 go 关键字,chan 关键字还有 sync.WaitGroup 大约就是会帮助你创建新的线程,同步结果。
我这里有一个 results 的 channel 同步结果,wg 指示搜索帖子的线程的结束。 然后我遍历了我要访问的社区链接,并且对社区返回的结果做解析。还有一个线程负责同步所有结果,最后在命令行输出结果。
针对不同的网站要有不同的解析方案。所以这就有了 matcher 接口,定义如下:
type Matcher interface {
match(reader io.Reader) ([]*Result, error)
}
matcher 接收的参数是 io.Reader,大约就相当于 JS 里面可以传任意参数吧,或者说就是最灵活的写法之一了。
对于 cnode 社区这样有提供 restful 接口的,自然是要解析 json 了。
type CNodeTopic struct {
Title string `json:"title"`
CreateAt time.Time `json:"create_at"`
Content string `json:"content"`
}
type CNodeResp struct {
Success bool `json:"success"`
Data []CNodeTopic `json:"data"`
}
type CNodeJSON struct {}
cnode 的每一个话题有好几个属性,我就只挑我要的了。
然后是解析:
func (CNodeJSON) match(reader io.Reader) ([]*Result, error) {
resp, err := ioutil.ReadAll(reader)
if err != nil {
return nil, err
}
cnodeResp := CNodeResp{}
if err = json.Unmarshal(resp, &cnodeResp); err != nil {
return nil, err
}
if !cnodeResp.Success || cnodeResp.Data == nil {
return nil, fmt.Errorf("no response")
}
ret := make([]*Result, 0)
for _, topic := range cnodeResp.Data {
if time.Since(topic.CreateAt).Nanoseconds() - time.Hour.Nanoseconds() * 24 * dayLimit > 0 {
continue
}
ret = append(ret, &Result{title: topic.Title, email: emailRe.FindString(topic.Content), content:topic.Content})
}
return ret, nil
}
各种 Golang 日常解析,出错就 return。如果一切都正常,那么自然是要判断发帖时间。是新帖子就加入到结果当中,没啥可说的。
但是大多数网站可没有 cnode 那么方便了,必须解析 html。
所以我就拿我 studygolang.com 举个栗子。
首先必须引用 goquery,它是一个类似 jQuery 或者说是更像 Node 里面的 cheerio 的工具,不用这个的话就要自己递归搜索 html 节点了。。。
go get "github.com/PuerkitoBio/goquery"
然后是解析:
type StudyGolangHTML struct {}
func (StudyGolangHTML) match(reader io.Reader) ([]*Result, error) {
doc, err := goquery.NewDocumentFromReader(reader)
if err != nil {
return nil, err
}
ret := make([]*Result, 0)
doc.Find(".topic").Each(func(i int, selection *goquery.Selection) {
abbr := selection.Find("abbr")
timeStr, _ := abbr.Attr("title")
t, err := time.Parse("2006-01-02 15:04:05", timeStr)
if err != nil {
return
}
if time.Since(t).Nanoseconds() - time.Hour.Nanoseconds() * 24 * dayLimit > 0 {
return
}
link := selection.Find(".title a")
ret = append(ret, &Result{title: link.Text(), email: "", content:link.AttrOr("href", "")})
})
return ret, nil
}
studygolang.com 的每一个主题的节点都可以用 .topic 选中,时间在 abbr 标签中,而标题和链接都在 .title a 下。
如果你有自己想要搜索的网站,比如 rust-china,kotlin-china 什么的,一般都还是 json 或者 html 的解析,应该不会很难适配。
结语
你居然看完了,祝你能尽快找到适合工作。










