

写在前面
本文会到你了解jwt的实现原理,以及base64编码的原理。同时本人也简单的实现了一下jwt的生成,点这里。
jwt是什么
本质上它是一段签名的 JSON 格式的数据。由于它是带有签名的,因此接收者便可以验证它的真实性。同时由于它是 JSON 格式的因此它的体积也很小。 JSON Web Token (JWT)是一种开放标准(RFC 7519),其中定义了一种紧凑 (compact) 且自包含(self-contained)的方式用于以JSON对象的形式在多方之间传递信息。信息可以被核实和信任,因为它经过了数字签名。JWT既可以使用密钥(采用HMAC算法),也可以使用公私钥(采用RSA算法)进行签名
为什么需要jwt
http的协议是无状态的,所有很长一段时间内,我们利用session/cookie来客服,服务器端存储session,客户端存储一个sessionid,访问时客户端带着sessionid,服务器根据对应的session,来确定是否该用户是否有相应的权限以及如何展现这个页面;但是目前随着终端设备的增多,比较流行的开发模式为前后端分离,也就是说后端趋向于服务化,提供相应操作的接口,RESTful API是目前比较成熟的一套接口规范;而RESTful API倡导的就是无状态,而无状态可以利用今天所说的jwt来实现。session这种有状态的方式,要大量的占用服务器的内存,同时当项目很大时,可能需要借助于redis集群来存储session。利用jwt可以将用户状态权限等放到客户端,服务端根据传过去的token来判断是否有访问这个资源的权限。
jwt的组成
jwt包含了三部分,用.进行分隔:
- 头部(header)
- 载荷(payload)
- 签名(Signature)
下面来一步步的生成这个token,先利用一个数组来保存这三个部门,声明一个数组const res = [];,得到三个部分后,利用res.join('.')来生成所需的token就好。
头部
头部中很一般包含两部分,token的类型与采用的加密算法,如:
const header = {
alg: 'HS256',
typ: 'JWT'
};
而后将,这个进行序列化并且转化为base64编码,需要注意的是**jwt中对应的base64并不是一个严格意义上的base64,由于token有可能被做为url,而base64中的+/=三个字符会被转义,导致url变得更长,所以token的base64会将+转化为-、/转化为_、删除=**。
根据这个规则,来实现一下生成符合要求的base64的函数:
const getBase64UrlEscape = str => (
str.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '')
);
const getBase64Url = data => getBase64UrlEscape(
new Buffer(JSON.stringify(data)).toString('base64')
);
实现了这个公共函数后,生成header就变得很简单了:
res.push(getBase64Url(header));
载荷
载荷中包含了声明,声明是对于用户的叙述以及其他的元数据。含有三种类型的声明:
- 保留声明,如
exp,sub等 - 公有声明
- 私有声明,私有声明为自定义的
对于载荷来说,个人倾向于在里面存储一些无关紧要的东西,如用户名,用户权限,用户id等:
const payload = {
username: 'zp1996',
id: 1,
authority: 32
};
第二部分就是将payload转化为base64编码:
res.push(getBase64Url(payload));
签名
签名就是将编码后的头部、载荷,利用相应的密钥应用相应的加密算法进行加密:
sha256(
`${base64UrlEncode(header)}.${base64UrlEncode(payload)}`,
secret
)
支持的算法一般有:
const algorithmMap = {
HS256: 'sha256',
HS384: 'sha384',
HS512: 'sha512',
RS256: 'RSA-SHA256'
};
const typeMap = {
HS256: 'hmac',
HS384: 'hmac',
HS512: 'hmac',
RS256: 'sign'
};
首先先来了解一下关于加密的几种算法:
- Hash加密—
crypto.createHash()
通过散列可以把任意长度的输入转化为固定长度的输出,输出的值就为散列值。如果两个散列值是不相同的,那么原始输入一定不相同;但是两个散列值是相同的,只能说原始输入有很大的可能是相同的;因为散列函数有可能会发生“碰撞”。hash很快,问题也在于很快。虽说加密之后不可以逆推,但是可以通过彩虹表的方式来破解,由于hash是很快的,根据彩虹表来与待破解的加密字符进行比对,很快就会得出我们想要的结果。当然一般的会进行加盐的操作,来增加这个时间成本。回到今天说的jwt,jwt对于安全的要求还是很高的,jwt的前两个部分就是一个经过加工的base64,肯定可以转义出来的,假设我们最后一个的签名部分都被解密出来了,那么token就可以被任意伪造,应用也就没有了安全性可言。所以jwt在生成签名时并没有采取Hash加密。
- Hmac加密—
crypto.createHmac()
先来看一下hmac的高大上的定义:密钥相关的哈希运算消息认证码。利用消息认证码可以确保消息不是被别人伪造的,消息认证码是带密钥的hash函数,由于hmac有了一个key,所以会比hash有更好的安全性。
- Sign加密—
crypto.createSign()
除了对数据进行加密和解密外,还需要对于数据传输过程中的完整性,安全性是否得到了保证。所以需要采用的就是Sign算法,该算法主要利用的是不对称加密算法,利用私钥进行签名,公钥验证数据的完整性。整个过程可以参见下图:
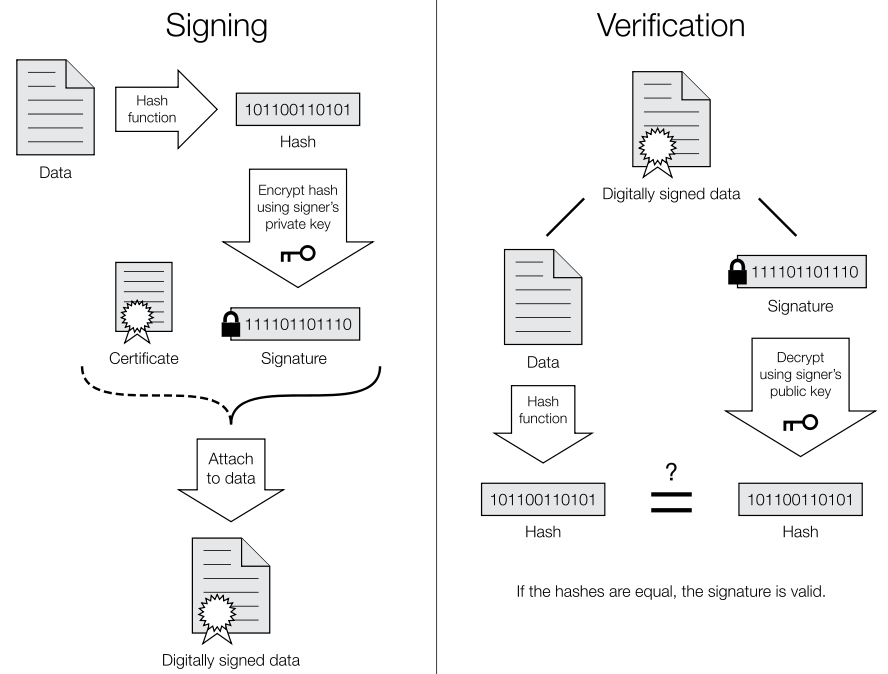
私钥和公钥利用openssl来生成,下面来看一个例子:
const fs = require('fs'),
crypto = require('crypto'),
data = 'zp1996',
alg = 'RSA-SHA256';
const signer = (method, key, input) =>
crypto.createSign(method)
.update(input)
.sign(key, 'base64');
const verify = (method, pub, sign, input) =>
crypto.createVerify(method)
.update(input)
.verify(pub, sign, 'base64');
const sign = signer(alg, fs.readFileSync('./private.pem'), data);
console.log(verify(
alg,
fs.readFileSync('./public.pem'),
sign,
data
)); // true
jwt中生成签名的方式
jwt中主要利用了hmac与sign,于是我们就可以写出生成签名的方法:
const cryptoMethod = {
hmac: (method, key, input) => crypto.createHmac(method, key).update(input).digest('base64'),
sign: (method, input) => crypto.createSign(method).update(input).sign(key, 'base64')
};
至此,我们就可以写出一个完整的sign方法了:
const sign = (input, key, method, type) => getBase64UrlEscape(
cryptoMethod[type](method, key, input)
);
/*
* payload 载荷
* key 密钥
* algorithm 加密算法
* type 采用何种类型 hmac or sign
*/
jwt.sign = (payload, key, algorithm = 'HS256', options = {}) => {
const signMethod = algorithmMap[algorithm],
signType = typeMap[algorithm],
header = {
typ: 'JWT',
alg: algorithm
},
res = [];
options && options.header && Object.assign(header, options.header);
res.push(getBase64Url(header));
res.push(getBase64Url(payload));
res.push(sign(res.join('.'), key, signMethod, signType));
return res.join('.');
};
至此就可生成一个比较合格的token了,下面就来实现验证与解析:
解析
解析出header和payload,这件事说白了其实就是将base64转化为普通字符串,而后再将字符串反序列化就可以得出。难点在与token的base64是被加工过得,对于替换的情况很容易转化回去,利用正则很容易做到,但是对于去除的=要怎么补回去呢?为什么就要去除这个=呢?它有什么特殊的地方吗?我想,有必要来看一下base64的原理:
base64原理
base64字符集
base64是一种基于64个可打印字符来表示二进制数据的方法,包括A-Z、a-z、0-9、+、/,以及一个补位用的=,实际上来看是65个字符,来看一张base64索引表:
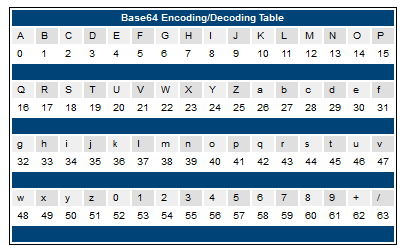
基本原理:
将每3个8字节转换为4个6字节,然后将转换后的4个6字节高位添加2个0,组成4个8字节,所以base64要比原字符串的大1/3左右,来看一个例子,如何将zpy转化为base64编码:
首先确定ascii码,分别为122,112,121,由于只有两个字符,所以后面的一个字符对应的二进制为00000000,于是构成的24位为:
01111010 | 01110000 | 01111001
以六位为一个部分进行分割:
011110 | 100111 | 000001 | 111001
对高位进行补0的操作,再将其转化为10进制:
30 | 39 | 1 | 57
在结合上图的索引表来看,很容易得出最终的值为enB5,由这个规则来看,我们很容易得出的是zp为enAA,但是利用new Buffer('zp').toString('base64')得出的为enA=,仔细来看base64还有两项规则:
- 两个字节的情况:将这两个字节的一共16个二进制位,按照上面的规则,转成三组,最后一组除了前面加两个0以外,后面也要加两个0。这样得到一个三位的Base64编码,再在末尾补上一个"="号。
- 一个字节的情况:将这一个字节的8个二进制位,按照上面的规则转成二组,最后一组除了前面加二个0以外,后面再加4个0。这样得到一个二位的Base64编码,再在末尾补上两个"="号。
解析token
base64的原理搞清楚了,那如何给token添加=也就很明白了,无外乎是在结尾加一个还是两个。base64编码长度一定是4的倍数,所以只需要在%4之后进行加=操作就好,结果只可能有两种情况:
- 2,添加两个
= - 3,添加一个
=
所以可以写出下面代码来将token转化为一个真正的base64:
const getBase64UrlUnescape = str => {
str += new Array(5 - str.length % 4).join('=');
return str.replace(/\-/g, '+')
.replace(/\_/g, '/');
};
到这里,解析方法就可以很容易的出来了:
const decodeBase64Url = str => JSON.parse(
new Buffer(getBase64UrlUnescape(str), 'base64').toString()
);
jwt.decode = (token) => {
const segments = token.split('.');
return {
header: decodeBase64Url(segments[0]),
payload: decodeBase64Url(segments[1])
};
};
验证
前面基本都理解了,验证其实很简单,就是利用密钥,来比对,看是否正确验证:
const verifyMethod = {
hmac: (input, key, method, signStr) => signStr === sign(input, key, method, 'hmac'),
sign: (input, key, method, sign) => {
return crypto.createVerify(method)
.update(input)
.verify(key, getBase64UrlUnescape(sign), 'base64');
}
};
写在最后
本文只是本人的一点愚见,如有错误,欢迎大家指出。