


编者按:这篇文章是关于Kubernetes 1.3新功能的一系列深入的文章的一部分。本文是第三篇。
使用Kubernetes的客户能够迅速响应终端用户的请求,交付软件也比以往更快。但是,当你的服务增长速度比预期更快时,计算资源不够时,该怎么处理呢?
此时可以很自豪地说:Kubernetes 1.3提供了一个解决方案:自动伸缩(auto-scaling)。搭建在Google计算引擎(GCE)和Google容器引擎(GKE)(以及即将用于AWS)上,Kubernetes会在必要时自动扩容你的集群,并在不需要时缩容,以便为你省下一笔费用。
Part 1:自动伸缩的优势
这里我们用一个例子说明自动伸缩的应用场景。
想象一下你有一个7*24(全天候)的服务,它的负载随着时间变化。在美国地区,白天服务非常繁忙,夜间负载相对较低。
理想情况下,我们希望集群中节点和运行中Pod的数量能够动态调整负载,以适应终端用户的需求。新的 自动伸缩 功能与 Horizontal Pod Autoscaler配合在一起可以自动解决这个问题。
Part 2:在GCE设置Autoscaling
以下操作指南适用于GCE。对于GKE请在集群操作手册(查看“相关链接”)查看 autoscaling这个章节。
开始之前,我们需要一个活跃的GCE项目,并且启用Google Cloud Monitoring、Google Cloud Logging和Stackdriver。
如果你想了解如何创建一个GCE项目,请阅读入门指南(查看“相关链接”)。我们还需要下载一个Kubernetes项目的最新版本(版本v1.3.0+)。
第一步:创建一个集群,并启用Autoscaler。
集群中的节点数量将从2开始,并自动调整到最大5。要实现这一点,我们需要设置以下环境变量:

通过kube-up.sh启动集群:

kube-up.sh 脚本创建一个集群,并默认启用了Autoscaler插件。如果集群中存在pending pod,autoscaler将尝试向集群中添加新的节点,然后pending的pod会被调度到新节点上。
我们观察一下集群,它应该有两个节点:

第二步:运行并暴露PHP-Apache 服务
为了演示自动伸缩功能,我们基于php-apache镜像制作了一个自己的镜像。镜像可以在这里(见“参考链接”)找到。它定义一个index.php页面,这个页面会执行CPU密集的计算。
首先,我们创建一个deployment,并将其端口暴露出来:

现在,我们将等待一段时间,验证部署和服务是否被正确创建和运行:
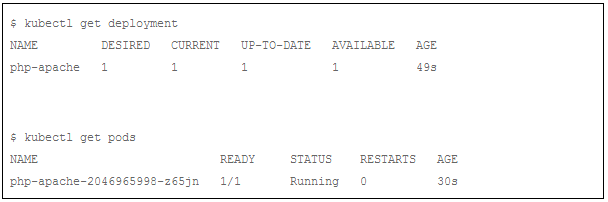
使用wget命令检查 Php-apache服务是否运行正常:

第三步:启动Horizontal Pod Autoscaler
depleoyment正常运行后,我们将为它创建一个Horizontal Pod Autoscaler对象。使用kubectl autoscale 命令就可以:

这里我们定义了一个Horizontal Pod Autoscaler,它保证deployment对象php-apache控制的Pod数量在1~10之间。
换句话说,horizontal autoscaler通过deployment对象增加或减少Pod副本数量,以保证所有Pod的CPU平均使用率在50%左右。
kubectl run创建deployment时,为每个Pod申请了0.5核CPU,也就是说,每个Pod实际平均使用0.25核CPU)。
关于该算法的详细信息查看文章末尾(“相关链接”)。
我们可以通过”kubectl get hpa”检查autoscaler 的状态:

注意,当前的CPU 使用率是0%,因为我们没有向服务器发送任何请求(当前列显示的是与hpa对应的rc下所有pods 的CPU使用率的均值。
第四步:提高负载
现在,我们将看到 Autoscalers(Cluster Autoscaler 和 Horizontal Pod Autoscaler)如何响应不断增加的负载。我们将启动两个实例(请运行在不同的终端),每个实例启动一个访问php-apache服务的死循环:

我们需要稍微等待一段时间(1min左右),然后检查Horizontal Pod Autoscaler的状态:
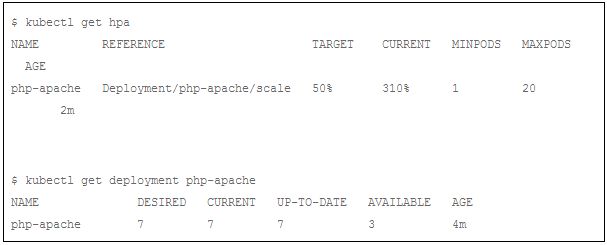
Horizontal Pod Autoscaler 已经把 Pod 数量增加到7。我们检查下是不是所有的Pod都在运行:
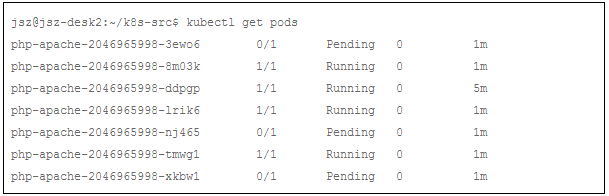
我们可以发现:一些 pod处于pending状态。我们使用 ”kubectl describe” 命令查看其中一个pending pod,以获取 pending 的原因:
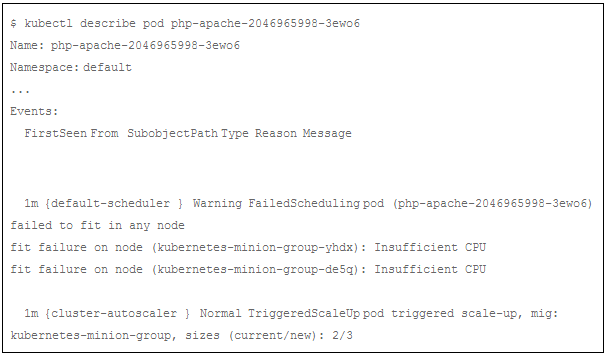
该pod正在pending 是由于在系统中没有足够的 CPU资源。我们还可以看到有一个 TriggeredScaleUp事件。这意味着 pod触发了Cluster Autoscaler 的响应,一个新节点将被添加到集群中。
现在我们再等待一段时间(3min左右),并列出所有节点:
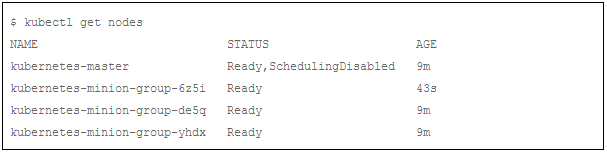
我们可以发现:一个新节点 kubernetes-minion-group-6z5i 被Cluster Autoscaler 添加到集群中。我们确认下所有的pods都已经运行正常:
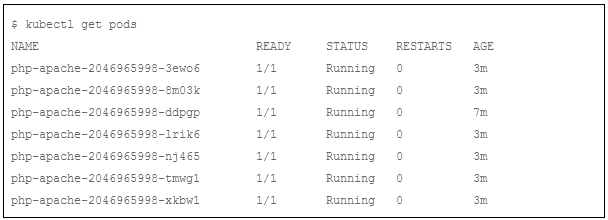
添加节点以后,所有的php-apache pods都在正常运行!
第五步:降低负载
现在,我们停止向服务器打压力。我们把两个向server发请求的死循环都结束掉,然后观察php-apache 服务的状态:
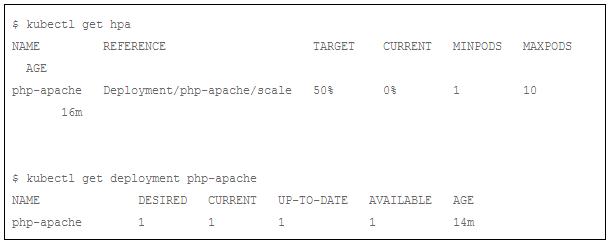
我们可以看到,Pod的CPU平均使用率已经降到0%,Pod个数也降到1。
把多余的Pod删除以后,大部分的集群资源都都被空出来。短时间内,集群不会被缩容,因为Cluster Autoscaler必须确保php-apache服务对资源的需求确实降低了,而不是短期或临时原因(比如Pod升级)。
更多细节参考 Cluster Autoscaler的文档(“相关链接”)。
集群缩容可能比扩容花费更多时间。大约10-12分钟后,您可以验证集群节点数量的下降:
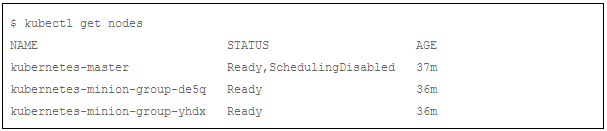
集群中节点的个数重新恢复到2, 节点kubernetes-minion-group-6z5i已经被Autoscaler删除。
Part 3:其他使用场景
看完上面的例子,我们可以发现,结合Horizontal Pod Autoscaler 和 Cluster Autoscaler动态调整pods数量是很简单的。
在有些场景下,Cluster Autoscaler 自己也能发挥不少作用,尤其是应对某些不规则的负载变化。
举个例子,与集群相关的开发或者集成测试一般不会在周末和晚上进行。
对于批处理集群,当所有Job都结束,而新的Job也只能在几个小时后才开始。
让机器闲着绝对是暴殄天物。
在这些场景下,Cluster Autoscaler 能够减少空闲结点的数量,并显示减少支出,因为你只需要为实际运行的服务付费,同时也能够保证你总是有足够的资源运行你的任务。
相关链接
GKE Autoscaling:https://cloud.google.com/container-engine/docs/clusters/operations#create_a_cluster_with_autoscaling
Cluster Autoscaler文档:https://github.com/kubernetes/kubernetes.github.io/blob/release-1.3/docs/admin/cluster-management.md#cluster-autoscaling
原文链接:http://blog.kubernetes.io/2016/07/autoscaling-in-kubernetes.html
