


从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可以帮助我们迅速建立web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站,个性化网站,我们自己的Geek网站!!
目录:
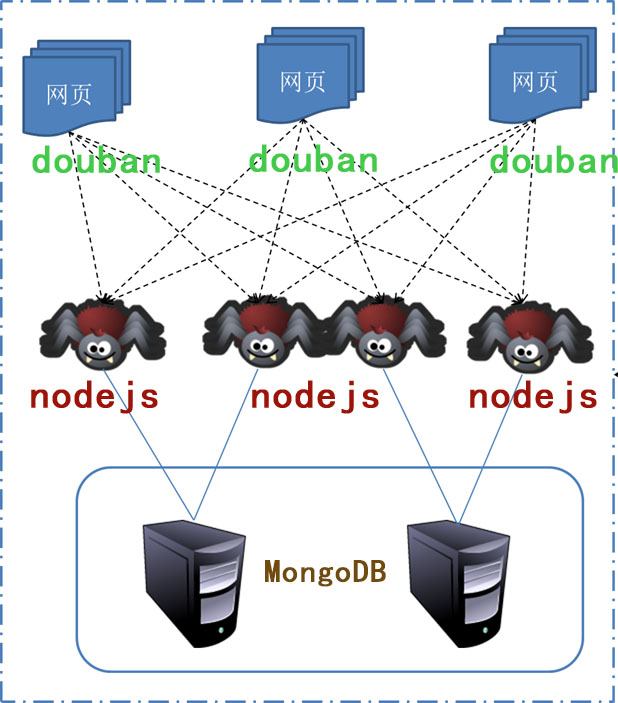
使用类库介绍 win7安装jquery – 失败 ubuntu安装jQuery – 成功 豆瓣爬虫
11 回复



-
URL改个参数,就可以传各种URL了 http://movie.douban.com/subject/11529526/
-
解析网页与jquery
-
代理服务器,自动切换IP,是完善的事情不是础功能。
-
cookie,不需要登陆的网页,不用做cookie



